
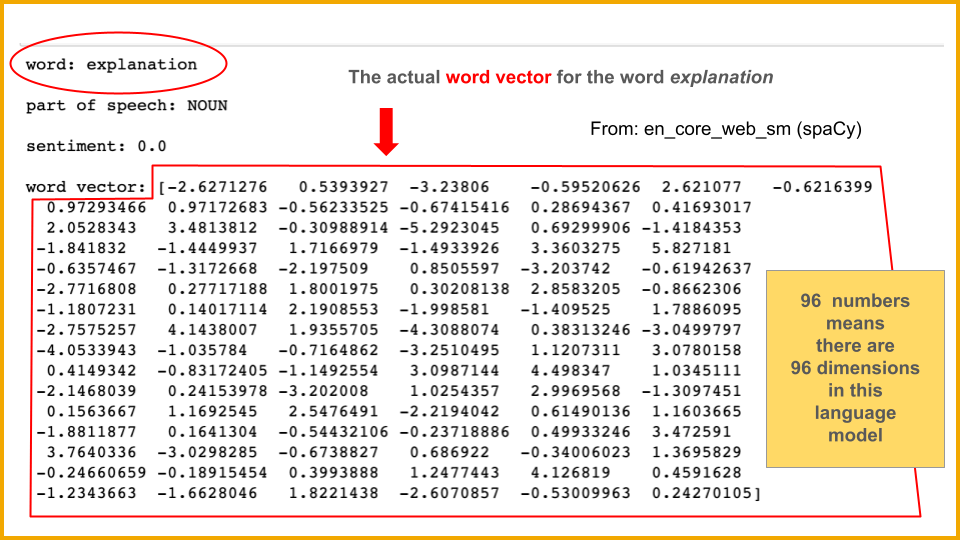
It was a challenge for me to figure out how to teach non–computer science students about word vectors. I wanted them to have a clear idea of how words and their meanings are represented for use in an AI system — otherwise, I worried they would assume something like a written dictionary with text and definitions. I also wanted them to know that it wasn’t something simple like “each word has a numerical code assigned to it.” So we spent some time talking about what a vector is and what “n-dimensional space” means.

Now I need to work out how to teach them about transformers. I found a surprisingly clear article at Orange.com (formerly France Télécom), on their Hello Future website about research and innovation. I’m going to quote a large section from that article:
“Originally, in 2013, word embeddings (such as Word2Vec, Glove, or Fasttext) were able to capture representations of words in the form of vectors taking into account the context of neighboring words in large volumes of text. Two words appearing in similar contexts were ‘embedded’ into N-dimensional space, to neighboring points in this space. This approach has led to significant advances in the field of NLP, but also has its limitations. From 2018 a new way of generating these word vectors emerged. Rather than selecting the vector of a word in a previously learnt static ‘dictionary,‘ a model is responsible for dynamically generating the vector representation of a word. A word is thus projected to a vector not only according to its prior meaning, but also according to the context in which it appears. The models for effective realization of these contextual projections (BERT, ELMO and derivatives, GPT and its successors) are based on a simple yet powerful architecture called Transformer.” (Spelling and punctuation edited for American English.)
I know that paragraph might not make sense if you haven’t already learned about word vectors. The key is that transformers are able to build on and enhance the machine accuracy of what a word or sentence means by taking into account its context in the current data. So you do have a language model, previously trained on a large corpus, but the transformer analyzes the present text input in a more holistic way, transforming the vectors as it goes.
Again quoting from the Orange.com article: “While previous approaches … could model contextual dependencies, they were always constrained by referencing words by their positions [in the sentence]. Attention is about referencing by content. Instead of looking for relationships with other words in the context at given positions, attention allows you to search for relationships with all words in the context, and through a very effective implementation, it allows you to rely on the most similar words to improve prediction, whatever their position in context.”
The role of the attention module is explained in a 2017 paper that, according to Google Scholar, has been cited more than 20,000 times: Attention Is All You Need. See the PDF for diagrams of the Transformer network architecture.
Language models produced by transformers include BERT (developed by Google, and which powers Google searches), ELMo, and GPT-3. These so-called large language models have raised many concerns, particularly around ethics, as their interior processes are a black box, and their immense training data has included biased and toxic texts. The Orange.com article includes two charts that illustrate differences among BERT, ELMo, and three generations of GPT.
An important aspect of transformers is that they produce these large language models from unlabeled data, and when developing applications based on transformers and such models, good results can be obtained with only a small amount of additional training data (“few-shot learning”).
Orange — like many other companies — is using large language models for classification and information-extraction tasks such as: “sentiment analysis, personal data detection, detection and identification of named entities, syntactic dependency analysis, semantic parsing, co-reference resolution,” and question answering. These tasks involve customer-service applications as well as internal data analysis.
Much of this post is based on the article The GPT-3 language model, revolution or evolution? (February 2021).
.

AI in Media and Society by Mindy McAdams is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
Include the author’s name (Mindy McAdams) and a link to the original post in any reuse of this content.
.