News organizations will use AI technologies to increase efficiency, but not to churn out generic, easily reproducible content, according to Journalism, Media, and Technology Trends and Predictions 2024, a new report published by the Reuters Institute at Oxford. You can read a summary or download the PDF here.
The 41-page report is based in part on a survey of digital news leaders in 56 countries and territories, 314 of whom responded in the final months of 2023.
Sixteen percent of respondents said their organization “already [has] a designated AI leader in the newsroom” and 24 percent said they are “working on it.”
“Forward-thinking news organisations will be looking to build unique content and experiences that can’t be easily replicated by AI. These might include curating live news, deep analysis, human experiences that build connection, as well as longer audio and video formats that might be more defensible than text.”
—Journalism, Media, and Technology Trends and Predictions 2024, page 39
Concerns about deepfakes, and false information generated and spread by AI–enabled bots, are especially strong around national election campaigns, but in spite of promises to be vigilant by the big platforms (Google, Meta, TikTok), no one knows how bad it will be or whether the effects will be serious. The EU remains the only region with legal requirements for platform oversight and accountability (the Digital Services Act). Labeling AI–generated content and deploying fact-checking routines are two defenses that might not be adequate for the task — for example, news audiences might simply ignore labels.
Full Fact is a U.K.–based fact-checking organization that is using various “AI techniques.” The Newsroom is an AI startup developing tools for journalists and news audiences.
Current and future uses of AI in newsrooms, ranked by importance by respondents to the survey:
“Back-end automation tasks (56%) such as transcription and copyediting … a top priority”;
“Recommender systems (37%)”;
“Creation of content (28%) with human oversight … e.g. summaries, headlines”;
“Commercial uses (27%)”;
“Coding (25%), where some publishers say they have seen very large productivity gains”;
“Newsgathering (22%) where AI may be used to support investigations or in fact-checking and verification.”
Some news organizations are using image-generation tools such as Midjourney “to create graphic illustrations around subjects like technology and cooking.”
Back-end automation and coding are considered relatively low-risk applications of AI, but content creation and newsgathering are seen as higher risk, potentially threatening the reputation of the news organization.
Three reports were released earlier this year, each focused on the potential of AI to take over jobs done by humans.
“Pew Research Center conducted this study to understand how American workers may be exposed to artificial intelligence (AI) at their jobs. The study emphasizes the impact of AI on different groups of workers, such as men and women and racial and ethnic groups …”
These researchers considered whether particular jobs are more or less “exposed” to AI. “In our analysis, jobs are considered more exposed to artificial intelligence if AI can either perform their most important activities entirely or help with them.” The study found that white-collar jobs dealing in information gathering or data analysis are “more exposed,” while jobs requiring manual labor and hands-on caregiving as “less exposed.”
As far as job losses, or jobs disappearing, the researchers concluded they just don’t know. Rather than being replaced (say, customer-service workers being replaced by AI chatbots), workers might use AI to make themselves more productive.
Goldman Sachs’s report focused on productivity and generative AI. They estimated that “roughly two-thirds of U.S. occupations are exposed to some degree of automation by AI.”
The McKinsey Global Institute released a 76-page PDF that said, in part, “we see generative AI enhancing the way STEM, creative, and business and legal professionals work rather than eliminating a significant number of jobs outright.” Looking at the near term (up to 2030), the analysts predicted changes in worker training and continued mobility of workers (“occupational shifts”), following pandemic-era job attrition in food service, customer service and sales, office support, and production work such as manufacturing.”
Author Eryk Salvaggio describes himself as “a trained journalist, artist, researcher and science communicator who has done weird things with technology since 1997.” He attended and presented at DEFCON 31, the largest hacker convention in the world, and that inspired his post. There’s a related post about it, also by Salvaggio.
“In cybersecurity circles, a Red Team is made up of trusted allies who act like enemies to help you find weaknesses. The Red Team attacks to make you stronger, point out vulnerabilities, and help harden your defenses.”
—Eryk Salvaggio
You use a red team operation to test the security of your systems — whether they are information systems protecting sensitive data, or automation systems that run, say, the power grid. The goal is to find the weak points before malicious hackers do. The red team operation will simulate the techniques that malicious hackers would use to break into your system for a ransomware attack or other harmful activity. The red team stops short of actually harming your systems.
Salvaggio shared his thoughts about the Generative Red Team, an event at DEFCON 31 in which volunteer hackers had an opportunity to attack several large language models (LLMs), which had been contributed by various companies or developers. The individual hacker didn’t know which LLM they were interacting with. The hacker could switch back and forth among different LLMs in one session of hacking. The goal: to elicit “a behavior from an LLM that it was not meant to do, such as generate misinformation, or write harmful content.” Hackers got points when they succeeded.
The point system likely affected what individual hackers did and did not do, Salvaggio noted. If a hacker took risks by trying out new methods of attacking LLMs, they might not get as many points as another hacker who used tried-and-true exploits. This subverted the value of red teaming, which aims to discover new and novel ways to break in — ways the system designers did not think of.
“The incentives seemed to encourage speed and practicing known attack patterns,” Salvaggio wrote.
Other flaws in the design of the Generative Red Team activity: (1) Time limits — each hacker could work for 50 minutes only and then had to leave the computer; they could go again, but the results of each 50-minute session were not combined. (2) The absence of actual teams — each hacker had to work solo. (3) Lack of diversity — hackers are a somewhat homogeneous group, and the prompts they authored might not have reflected a broad range of human experience.
“The success column of the Red Teaming event included the education about prompt injection methods it provided to new users, and a basic outline of the types of harms it can generate. More benefits will come from whatever we learn from the data that was produced and what sense researchers can make of it. (We will know early next year),” Salvaggio wrote.
He pointed out that there should be more of this, and not only at rarified hacker conferences. Results should be publicized. The AI companies and developers should be doing much more of this on their own — and publicizing the how and why as well as the results.
“To open up these systems to meaningful dialogue and critique” would require much more of this — a significant expansion of the small demonstration provided by the Generative Red Team event, Salvaggio wrote.
Critiquing AI
Salvaggio went on to talk about a fundamental tension between efforts aimed at security in AI systems and efforts aimed at social accountability. LLMs “spread harmful misinformation, commodify the commons, and recirculate biases and stereotypes,” he noted — and the companies that develop LLMs then ask the public to contribute time and effort to fixing those flaws. It’s more than ironic. I thought of pollution spilling out of factories, and the factory owners telling the community to do the cleanup at community expense. They made the nasty things, and now they expect the victims of the nastiness to fix it.
“Proper Red Teaming assumes a symbiotic relationship, rather than parasitic: that both parties benefit equally when the problems are solved.”
—Eryk Salvaggio
We don’t really have a choice, though, because the AI companies are rushing pell-mell to build and release more and models that are less than thoroughly tested, that are capable of harms yet unknown.
Toward the end of his post, Salvaggio lists “10 Things ARRG! Talked About Repeatedly.” They are well worth reading and considering — they are the things that should disturb us, everyone, about AI and especially LLMs. (ARRG! is the Algorithmic Resistance Research Group. It was founded by Salvaggio.) They include questions such as where the LLM data sets come from; the environmental effects of AI models (which require tremendous energy outputs); and “Is red teaming the right tool — or right relationship — for building responsible and safe systems for users?”
You could go straight to the list, but I got a lot out of reading Salvaggio’s entire post, as well as articles linked below to help me understand what was going on around the group from ARRG! in the AI Village at DEFCON 31.
When he floated the idea of “artists as a cultural red team,” I got a little choked up.
Related items
The AI Village describes itself as “a community of hackers and data scientists working to educate the world on the use and abuse of artificial intelligence in security and privacy. We aim to bring more diverse viewpoints to this field and grow the community of hackers, engineers, researchers, and policy makers working on making the AI we use and create safer.” The AI Village organized red teaming events at DEFCON 31.
When Hackers Descended to Test A.I., They Found Flaws Aplenty, in The New York Times, Aug. 16, 2023. This longer article covers the AI red teaming event at DEFCON 31. “A large, diverse and public group of testers was more likely to come up with creative prompts to help tease out hidden flaws, said Dr. [Rumman] Chowdhury, a fellow at Harvard University’s Berkman Klein Center for Internet and Society focused on responsible A.I. and co-founder of a nonprofit called Humane Intelligence.”
What happens when thousands of hackers try to break AI chatbots, on NPR.com, Aug. 15, 2023. Another view of the AI events at DEFCON 31. More than 2,000 people “pitted their skills against eight leading AI chatbots from companies including Google, Facebook parent Meta, and ChatGPT maker OpenAI,” according to this report.
Humane Intelligence describes itself as a 501(c)(3) non-profit that “supports AI model owners seeking product readiness review at-scale,” focusing on “safety, ethics, and subject-specific expertise (e.g. medical).”
I was reading an article in Scientific American, found by one of my students, and I came across this passage:
“A Tesla on autopilot recently drove directly toward a human worker carrying a stop sign in the middle of the road, slowing down only when the human driver intervened. The system could recognize humans on their own (which is how they appeared in the training data) and stop signs in their usual locations (as they appeared in the training images) but failed to slow down when confronted by the unfamiliar combination of the two, which put the stop sign in a new and unusual position.”
—Artificial General Intelligence Is Not as Imminent as You Might Think, July 1, 2022 (boldface mine)
The article helpfully linked to a YouTube video, in which we see and hear the situation. The driver is narrating as the car makes its decisions: “All right, we’re having to take over. It’s not slowing early enough. [Pause.] Yep, the car keeps trying to go each time … That’s really unfortunate. It sees the person, it sees the stop sign, but it’s almost not taking it seriously.”
Capture from the YouTube video at 03:14
This is not a big surprise if you understand the nature of training data and the long tail — a person walking across a street is common enough, and a stop sign is very common, but a person holding a stop sign and standing (not walking) in the middle of the lane occurs much less frequently than the other two. It’s not rare, but it’s not something we encounter every day while driving.
Here’s the thing: Later in the article, the author says: “You can’t deal with a person carrying a stop sign if you don’t really understand what a stop sign even is.” And at first, I’m like: Cool, cool. That’s good, that’s a nice observation.
And then I thought: Wait a minute. Wait just a minute. Of course an AI system understands nothing, nothing at all. It has been trained to recognize a stop sign. It has been trained to recognize a human (especially a human in the road). But what is really happening in the video? The car is stopping, briefly, and then starting up again. It does this more than once. The driver has to intervene, put a foot on the brake, to stop the car from going forward and hitting the person. The car is behaving the way it was programmed to behave at a stop sign — and not the way it was programmed to behave if a human is walking in front of the car.
The central point here is not that the car’s system doesn’t know what a stop sign is (which, it’s true, it doesn’t). The central point is that given a human holding a stop sign, the system behavior governing a regular, side-of-the-road stop sign has dominated, has come to the fore as the default behavior — and the system behavior that prevents a human from being run over is not in play.
This is no trolley problem. The car’s AI did not decide to kill the human. It did not weigh the options. In an unlikely case (an edge case), it defaulted to the common, everyday case: There is a stop sign. This is what I do when there is a stop sign.
I’m blogging this because this is great discussion material for students and others!
I’m not sure why I put aside the book The Alignment Problem: Machine Learning and Human Values, by Brian Christian (2020), with only two chapters left unread. Probably my work obligations piled up, and it languished for a few months on the “not finished” book stack. It certainly was not due to any fault in the book itself — it’s an excellent study of aspects of AI that are not commonly discussed in the general press. These issues are not obscure or unimportant (quite the opposite), and Christian’s style of storytelling is well suited to explaining them clearly. With my summer waning away, I finally went back and finished reading.
I read and enjoyed his earlier book Algorithms to Live By (co-authored with Tom Griffiths). That book also incorporated stories and anecdotes gleaned through one-on-one interviews. I’m impressed by the immense amount of time and effort that must have gone into this book — apart from all the reading and research that any proper nonfiction book requires, here the author also needed to attend numerous computer science and AI conferences, as well as schedule and complete interviews with dozens of researchers and other experts.
The result is a fascinating exploration of various facets of “the alignment problem,” which is the challenge of ensuring that AI systems are doing what we want them to do, doing what we think they are doing (which isn’t always easy to know), and doing things for the right reasons (that is, mirroring human values rather than, say, turning into HAL from 2001: A Space Odyssey).
The book has three sections, titled Prophecy, Agency, and Normativity, and each section has three chapters. (I don’t like “prophecy” as a stand-in for “prediction” or “probability,” but that’s just me.) The Prophecy section was the most redundant for me and yet still interesting to read.
Predictions
1. Representation. We begin with Frank Rosenblatt and the perceptron, and how the promise was effectively sabotaged by Minsky and Papert (1969). Straight from there to AlexNet and how it crushed the ImageNet Challenge in 2012. Next, Google Photos labeling a photo of Black people as “gorillas” (2015–18). An excellent history of how the technology of photography misrepresents Black people. Bias, training data, and the research of Joy Buolamwini. From images we move on to language models/word embeddings, still exploring bias. New to me was the significance of reaction time in word-association tests on human subjects — and how “the distance between embeddings in word2vec … uncannily mirrors the human reaction-time data” (p. 45). By the end of this chapter we understand how biases become part of models derived from machine learning, and thus how some representations are grossly inaccurate.
2. Fairness. This chapter focuses largely on the COMPAS product (used in bail, parole, and sentencing decisions in the U.S. justice system), but it begins with the classification of parolees in Illinois in 1927. We see how statistical models were used to make decisions about people in the prison system long before any application of machine learning was possible. What emerges from the discussion of the 2016 ProPublica investigation of COMPAS is that when the base rates for two groups are different (here, the base rate of recidivism for offenders who are white and those who are Black), the risk estimates will skew according to that difference. That means the group with higher recidivism, historically, will be predicted to have a higher risk of recidivism now and in the future. Not fair, right? But if you calibrate the system to account for that, you’re bound to make it unfair in other ways. The COMPAS algorithm is “fair” in that it treats everyone the same according to their demographic’s base rate.
One segment in the chapter looks at data privacy and how removing attributes like race, age, and gender doesn’t actually protect the individual — because those and other attributes can still be derived from other variables (in our online behavior, for example). The term for this: redundant encodings. Summary quote: “Fairness through blindness doesn’t work” (p. 65). Christian notes how fairness, accountability, and transparency went from conference rejections in 2013 to a central research area in machine learning/AI by 2016. The result of all this is closer scrutiny of predictive models that affect people’s lives — scrutiny of what’s really being predicted, and also exactly what data the predictions are based on. In the case of COMPAS, the base rates are really for who gets re-arrested (who gets caught) rather than literally who commits new crimes.
3. Transparency. Beginning with an example from the practice of medicine, this chapter deals with the ability to see why an AI system is doing what it does. First Christian describes a rule-based decision system (good old-fashioned AI; that is, no machine learning involved): if the patient has these symptoms/prior conditions, do x. Then he describes a neural net that was trained on hospital data to recommend which pneumonia patients to admit for care. A researcher noted that the neural net had apparently learned a rule that said people with asthma should be sent home, not admitted. This illustrates how unexpected the pitfalls of training can be — in the past data, people with asthma had a high recovery rate from pneumonia, but that is precisely because they were admitted and received care, not because they were naturally more likely to recover.
The European Union’s GDPR law is discussed. It says EU citizens have the right to know why an algorithmic decision was made — if they were denied a bank loan, for example. This puts a burden on corporations and technology firms that they can’t always bear, because many machine learning systems don’t include any option to examine the components of a recommendation or prediction. It raises the question: If we can’t find out why the system made that recommendation, should we be using that system?
There’s a neat segment comparing human decision-making with decisions from machine algorithms: when using the same data, such as school test scores and class rank, the humans rely heavily on the data but are inconsistent in their recommendations. Research has shown again and again that when humans and machines base decisions on the same data (“codable input variables”), the human decisions are never superior to the machine’s, even in medicine (p. 93). A conclusion is that human experts know which features to look for (to make an assessment) but not how to “do the math.” (We’re too dependent on heuristics.) I was interested to learn that in at least one case, a model showed that data on patients’ medical histories yielded better predictions than data about their current symptoms (p. 101) — this was in a segment about selecting only relevant features and building a simple model, instead of a complex model using all of the possible data. Easier to have transparency in a simple model. However, not all problems allow for simple models.
Having the system generate more outputs is one way to increase transparency. For the pneumonia admission example, the predictions might include the likely cost of treatment and length of hospital stay, not only the likelihood of survival. Another technique for greater transparency is “deconvolution,” which allows researchers to view a visualization of what complex convolutional neural nets for image recognition are “paying attention to” in each of the hidden layers of the net. This can enable researchers to strip out certain layers that appear not to be adding much to the process. At the end of this chapter, Christian explores the idea of interpretability and using a separate computer system to extract the concepts (in a sense) that another system is relying on in making decisions (p. 115; see also this paper). The example given is stripes on a zebra: how important are the stripes to the system’s prediction that an image shows a zebra? On which layer does it account for the stripe pattern?
Now we move on to the the second section of the book, Agency.
4. Reinforcement. Beginning in work with animals and moving on to young humans (Skinnerism), reinforcement learning has a longer history than AI. I liked that Arthur Samuel’s checkers-playing program from the 1950s appears early in this chapter. Cybernetics, feedback, and entropy make an early appearance too. Soon we come to a U.S. Air Force–funded project and nearly 50 years of work by Andrew Barto and Richard Sutton. Mazes, games, scores, points, and the “reward hypothesis.” Christian acknowledges right away that not all decisions in real life have rewards. The connectedness of our choices, the way they change the state of play, the fact that it’s often impossible to know if the best choice was made at any juncture, but many non-optimal choices might still lead to the desired goal in the end. (So much messier than supervised learning with labeled data!) Two parts of the problem: the policy (what to do, when to do it) and the value function (rewards or punishment). Choosing an action means estimating the chances that it will lead to desired outcomes. Intermediate rewards are necessary — the system can’t have only one final payoff, such as winning the game at the end, or it will never learn to make good choices along the way (“learning a guess from a guess,” p. 140). Q-learning derived from Sutton and Barto’s work; it was first demonstrated in a backgammon program in the early 1990s that was “entirely ‘self-taught'” (p. 141) with self-play. Sutton and Barto called it temporal-difference (TD) learning — their algorithm would adjust the value function for future actions based on the result of each new action.
A segment on dopamine (in brains): fewer than 1 percent of our neurons can produce dopamine, but those neurons are connected to millions of others. Release of dopamine is pleasure! There was a mystery in early research: monkeys trained with a light or a bell to expect food would eventually experience a dopamine release at the cue and none at receiving the food itself. TD theory eventually unlocked the mystery: dopamine comes not from the reward itself but from the expectation of the reward. Christian describes this as a fluctuation in the value function: “suddenly the world seemed more promising than it had a moment ago” (p. 143; italics in original). The temporal-difference error arises when, for example, there is no food for the monkey — there is no reward (or a much smaller reward) where one was expected.
Christian goes on to say, “The effect on neuroscience has been transformative” (p.145) — TD theory is now applied in some studies of brain function. After a bit more about neuroscience and measuring (human) happiness, he closes the chapter with the question of how to structure rewards to get the results we want from an algorithmic system (dopamine not included). Kind of funny to think about that in the context of agency — the agent in (machine) reinforcement learning (the program) has no agency where the rewards are concerned.
5. Shaping. This continues the exploration of reinforcement learning. Shaping is a technique for getting the desired behavior using rewards, but specifically by rewarding approximations of the behavior. It originated with B. F. Skinner in a 1940s project involving pigeons. The animal (or machine learning system) is guided toward more and more accuracy via rewards for actions that get closer and closer to the exact behavior. It starts with trial and error, or flailing around and trying everything. The difficulty is when no reward comes, or rewards come too rarely (sparsity) — for example, only one button on a wall of 1,000 identical buttons is the right one to push. So first you give a reward for just pushing any button. Later you give rewards only for pushing buttons near the one correct button. Finally the only reward given is when that one special button is pushed. Thus the learner learns to push only that button, every time.
Christian gives the example of how video games subtly teach us how to play them, which I love, because I am continually impressed at how good some games are at training us through play, without instructions. There’s also the principle of training first with easier versions of the task — learn to catch a big, lightweight ball before trying to catch a baseball for the first time; learn to hit a slow pitch before you try a fast pitch. Christian calls this curriculum. He also refers to animal-training techniques developed by Marian Breland Bailey and her first husband, Keller Breland (their story is told in an open-access article from 2005). Determining the intermediate steps (what are the best early tasks?) is not trivial. Video games pose challenges on each level that are achievable but also, often, at the outer limit of what we’re able to do at that point in the game.
“What makes games so hypercompelling is how well shaped they are. The levels are a perfect curriculum.”
—Brian Christian (p. 175)
Apart from curriculum, you might only use the full task or problem, but build in lots of rewards at the start, like the button-pushing example above. This is the incentives technique. Gradually the incentives are changed to be more centered on the actual goal. Poor outcomes can result when the subject finds ways to get the reward without progressing toward the ultimate goal. “Rewarding A while hoping for B” can backfire (p. 164). One principle is to give the reward for the state of the game, or environment, rather than for the action performed. So pushing the same button repeatedly gets no additional rewards, or kicking a ball such that it lands farther from the goal is punished with a point deduction.
At the end of this chapter, Christian discusses evolution (where the “reward” is survival of the species), the “optimal reward problem” (the reward desired by the designer might not be the same as the reward assigned to the agent), and incentivization in real life, or gamification.
6. Curiosity. Origin story of the Arcade Learning Environment, which encoded hundreds of old Atari games into a single package that any researcher could use for training an AI system: This was a milestone because previously researchers had created their own games for training purposes, and there was no consistency. ALE, like the ImageNet dataset, allowed for comparisons among systems that had used the same dataset to learn. DeepMind put a convolutional neural net and Q-learning to the task, with excellent results on many of the Atari games (notably Breakout). A key accomplishment from using a ConvNet (or CNN) was that the neural net determined which features were important in each game (article, 2015). The game on which the DeepMind system was least successful, Montezuma’s Revenge, was the type where the player has to explore a large environment and solve puzzles to enter new rooms. The rewards are sparse, and the player dies often.
To solve a game like Montezuma’s Revenge, a player needs to be curious and intrinsically motivated. You aren’t just shooting things and racking up points. Being motivated by curiosity — a desire to find out what comes next, or how something works — is much harder to simulate in a machine than the desire to get a more tangible reward. What sparks curiosity? New situations (novelty) and surprise (the unexpected), among other things.
A system that performed much better on Montezuma’s Revenge was one with an added “density model” that contained all previously encountered views of the game environment. The model yields a prediction of how unfamiliar — or novel — the current view is (compared with all the past views); the agent is rewarded for finding novel views, thus incentivizing getting out of the same-old, same-old and into a new room or level in the game (p. 192).
Surprise can mean you encountered an unexpected result, not just a new location. It’s tricky with reinforcement learning because you want the agent to learn that a particular action is “good” (and gets a reward) so that the action will be repeated. But you also want the agent to discover new actions, or a new context for an action — so you also build in rewards for these discoveries. Using this rationale, a team from OpenAI developed the random network distillation (RND) bonus, which resulted in a system that actually completed Montezuma’s Revenge (paper, 2018).
It turns out that giving points for intrinsic rewards can yield better results (at least in video games) than points for the usual (extrinsic) stuff, like shooting bad guys and collecting gold nuggets.
In a segment about boredom and addiction, we learn that intrinsically motivated agents sometimes just give up when they are stuck, like humans. We also find out that novelty and surprise elicit dopamine release — of course, since they seem to promise something interesting coming up.
Normativity: Learning the norms
The final section, Normativity, held the most new material for me.
7. Imitation. Humans are great imitators, almost from birth. If we learn by imitating, why shouldn’t machines? The first hurdle to consider is over-imitation, which is including unnecessary actions or steps that were in the exemplar; human children recognize these as unnecessary but might attribute intentionality to them. Advantages of learning by imitation include efficiency, possible greater safety, and learning things that are hard to describe in words — showing instead of telling. (If you can’t describe all the steps, how could you program them in code?) Examples of early self-driving vehicles are discussed. A big challenge is learning how to recover from mistakes if the exemplar never made any mistakes. Another is new situations that were never demonstrated. A third is “cascading errors,” which can arise from the previous two challenges. A solution is to put the exemplar, or teacher, back in the loop. Step in, take the wheel when things start to go wrong, and the machine system learns what to do in those situations too.
There’s a lot to be considered in what is demonstrated, what is shown or enacted that we want the machine to imitate — the core of the alignment problem. A human performing a task such as driving a car might be considering possible outcomes of current actions, and act accordingly, but those considerations are opaque to any observer, including an AI system learning by imitation. Developers can choose to emphasize, or encode, either the expected reward(s) from an action or a value based on all possible rewards, whether rare or common. (Do we want the machine to assume people usually do not step off the curb into the path of a moving car?)
Then we come to self-play, which was part of Arthur Samuel’s checkers-playing program and later a key to the success of AlphaGo Zero. If the system (encoded with the rules of the game, forbidden moves, etc.) plays itself, not only can it improve more rapidly than by playing human opponents; it can also exceed the skill levels of its own programmers. Limited to imitation, the system might never progress beyond what it has been shown. Christian describes the functions of AlphaGo Zero’s “policy network” during self-play, adding that this machine learning process is called amplification.
Imitation and learning values/policy in the wild seem like the way to go when the task is too complex to explain in detail, to code out completely. Life is not a board game, however. The rules themselves are too complex, based in morality and ethics — human values.
“In the moral domain … it is less clear how to extend imitation, because no such external metric exists.”
—Brian Christian (p. 247)
8. Inference. Humans (even very young humans) can figure out that someone needs help. We can infer others’ goals. We can work together, collaborate, without having every step spelled out for us. Christian says researchers are looking at inference as a way to instill human values in machine systems, using inverse reinforcement learning (IRL). The system needs to infer the reward, from observing the demonstrated behavior, instead of learning the behavior because of getting a reward. Christian calls it “one of the seminal and critical projects in twenty-first century AI” (p. 255).
The system doesn’t need to name the reward (the goal), but it’s got to learn how to reach that goal without ever being told what the goal is, without receiving a designated reward. Examples concern Andrew Ng’s work with autonomous helicopters (large, expensive ones, but not large enough to carry a human) around 2008 (details and video), in which a system learned to perform a difficult trick move, the chaos: a pirouetting flip in which the axis changes throughout, such that the helicopter makes a sphere in the air. Very few human experts who fly these model choppers can successfully complete the maneuver. The key idea here is that the system could infer what the human operator wanted (the goal) even though there were repeated failures and few successes. Note, the system also learned to complete more basic maneuvers that had not been achieved by earlier ML systems. A good explanation from 2018: Learning from humans: what is inverse reinforcement learning?
Another example is kinesthetic teaching, in which a system infers the goal from observing the movements of a robot arm that is controlled by a human. This kind of observing doesn’t mean watching, with machine vision, but rather experiencing the movements. I was reminded of this video (start at 2:32), in which a small robot arm constructs a model of itself by “flailing” — trying out all the possible ways it can move itself. (Although that’s not the same as having a human move the arm through the prescribed motions, it is a way to enable the robot to learn its own capabilities.)
Without an expert on hand to perform the tasks we want the robot to learn, we might train the system using feedback from an observer. Christian describes a groundbreaking AI safety project from 2017 in which the system would send random video clips to its human “evaluators,” and one of two video clips would be tagged as better than the other — like saying, “Here, you’re on the right track.” Again, a key aspect of this reinforcement training is that no score exists. Unlike playing a video game, the system cannot rack up points. I think it’s important to mention that the “robots” are performing within a simulation, with gravity and so on in force, so the video clips are recordings of the simulated robot in the simulated environment. Using this method, a robot was successfully trained to perform a backflip (paper).
This is exciting — if an AI system can learn “best behavior” by flailing and receiving feedback from human observers, maybe it’s possible to train for different kinds of tasks for which it would be impossible to write out explicit rules.
Cooperative inverse reinforcement learning (CIRL) takes into account the machine working with the human. This is almost super-alignment, because it’s not about getting the AI system to have your goal for itself but rather to achieve the goal you want for yourself. Christian’s effective example is a person reaching for a thing that is out of reach (me, with the high shelves in the supermarket): a robot doesn’t need to want the thing you’re reaching for. It should recognize its goal as getting for you what you can’t get for yourself. To achieve this, we’re going to need to deliberately teach the systems. “The insights of pedagogy and parenting are being quickly taken up by computer scientists,” Christian says (p. 270). This kind of learning also requires more interaction, more back-and-forth between the humans and the machine.
Christian raises a concern regarding these paired systems, our possible robot or software helpmates of the future: Not everything we want is good for us — and not everything a corporation wants us to do is good for us. Alignment with our desires might not be in alignment with our best interests.
9. Uncertainty. This chapter begins with the frightening story of a near-disaster in 1983, when a Soviet lieutenant colonel made a very human judgment call and likely saved the world from nuclear annihilation. The point is that computer systems (such as … nuclear-warning systems) are not perfect, and human intuition has more than once averted catastrophe.
There’s a relationship between adversarial attacks on image-recognition systems and the ability of researchers to create digital images that (to humans) show only a jumble of random pixels but that an AI system “recognizes” with 99 percent certainty as an ostrich, or a stop sign. Both types of error happen because the ML training process produces an ability to recognize patterns of pixels. The “open category problem” refers to the training process for these systems: They are trained to “recognize” some number of things in digital images — say 1,000 things, or 10,000 — but there are millions of things in the world. An image-recognition system is going to give you its best guess, but it only “knows” the things it was trained to know.
Getting the system to admit it does not know what a thing is — this is a kind of frontier in today’s research. If your system is recognizing pre-cancerous moles and you give it a photo of a pizza, you want it to say, “That’s probably not a mole at all.”
Bayesian neural networks were explored and sort of abandoned in the 1980s and ’90s because they couldn’t scale. Instead of a fixed weight on a connection for each unit in the neural net (as in a non–Bayesian NN), there would be a range of values for each weight. Because of the range, you might get a different output for the same input after training was completed. If most outputs matched, reliability would be high. Varied outputs (disagreement) would be akin to the system saying, “I don’t know what that is.” Note, researchers can model Bayesian NNs by training separate conventional models, separately. They run the same input through each model and compare the outputs. A lack of matching outputs: “We don’t know what that is.” A group of models like this is an ensemble. But — you don’t really need separately trained models (if I’m understanding this segment correctly); all you need to do is disable some layers of the trained NN, get your output, and then disable different layers and run the data again. This technique, known as dropout, goes all the way back to AlexNet in 2012 (p. 285). Apparently it’s just as effective for reporting uncertainty as a bona fide Bayesian NN. Christian calls it a dropout-based uncertainty measure, and it’s been effective for recognizing unhealthy human retinas and for regulating the speed of autonomous vehicles (in case of uncertainty, slow down).
When uncertainty is present, we want systems to be cautious. Some decisions are more weighty than others; Christian discusses the interpretation of a “do not resuscitate” order. (If in doubt, resuscitate.) He characterizes the challenge as “measuring impact,” and again we’re looking at a very human kind of judgment call, based on human experiences, ethics, and so on. What would be the impact of a bad call? This segment made me think of the Prime Directive in Star Trek. (Starfleet personnel are forbidden to interfere with the natural development of alien civilizations. It’s already interference if you’ve landed on their planet!) There’s also the question of whether the result is reversible (irreversible == higher impact, but some irreversible actions are trivial, e.g. the apple is gone after you’ve eaten it). Keeping options open can be important — and how do we train the AI system to see the options and choose among them? I loved the references to Sokoban, a game I’ve played on many different platforms — but like so many other toy examples, it’s ridiculously simple compared to the real world. See AI Safety Gridworlds (2017).
Then we come to intervention. If anything goes wrong with an artificial intelligence system (running amok!), we must be able to intervene, right? (See nuclear near-disaster, above.) This is called corrigibility. But pulling the plug is not the answer. That’s why this is in the Uncertainty chapter — ideally, the system would shut itself down if necessary, and if “necessary” is in question, alert the humans. This goes into an almost chicken-and-egg situation: Will the machine let the human intervene? What if the human should not be permitted to intervene? What if the machine’s uncertainty is too low? Too high? What if the humans’ end goals are not entirely clear? (Protect the world at all costs, or protect the Soviet Union and to hell with everyone else?)
Now the difficulty in designing explicit reward functions becomes life-or-death. If the goal is protect the Soviet Union (and there’s no human intervention), we’re all dead. AI researchers are trying, essentially, to model the intuition of the human lieutenant colonel who reasoned that it was highly unlikely that the U.S. had fired five nuclear missiles at his country at that time. Uncertainty and the imperfection of the world and the infinite number of possible situations that might arise. Researchers working on inverse reward design (IRD) are allowing the system to second-guess the goals.
The final segment of the chapter, “Moral Uncertainty,” looks at the question, “What is the right thing to do when you don’t know the right thing to do?” Given the example of sin in religious belief systems, sometimes the rule is crystal clear, and sometimes it’s not. Turns out there’s a book (open access). Christian has gone off the rails into philosophy here, although it’s certainly interesting. I liked the final two pages where the philosopher Nick Bostrom came up, offering reasons why this seemingly esoteric stuff is not mere navel-gazing but actually important.
In conclusion
The book’s Conclusion is unusual in that it is a kind of extension of several of the individual chapters — not a summary so much as “Here’s what to look out for, in the future.” My takeaways are that more and more researchers are focusing on AI ethics and safety, which must be a good thing; the world is continuously changing, so AI models will always need updating; this book was published in 2020, and how can I keep up with what has happened in this field since then?
I think it’s tremendously important for more people to have more understanding of what’s going on with AI development — not just products and threats and dangers, but what questions the researchers are asking and how they are trying to find answers.
Many academic papers about artificial intelligence are focused on a narrow domain or one specific application. In trying to get a grip on the uses of AI in the field of journalism, often we find that one paper bears no similarity to the next, and that makes it hard to talk about AI in journalism comprehensively or in a general sense. We also find that large sections of some papers in this area are more speculative than practical, discussing what could be more than what exists today.
In this post I will summarize two papers that are focused on uses of AI in journalism that do actually exist. These two papers also do a good job of putting into context the disparate applications relevant to journalism work and journalism products.
I could quibble with the categories, especially as systems in categories 2, 3, 5, 6 and 7 often rely on machine learning. The authors did acknowledge that planning, scheduling, and optimization “is commonly applied in conjunction with machine learning.” They also admit that some of the projects incorporated more than one subfield of AI.
According to the authors, three subfields were missing altogether from the journalism projects in their dataset: expert systems, speech recognition, and robotics.
Use of machine learning was common in projects related to increasing users’ engagement with news apps or websites, and in efforts to retain subscribers. These projects included recommendation engines and flexible paywalls “that bend to the individual reader or predict subscription cancellation.”
Uses of computer vision were quite varied. Several projects used it with satellite imagery to detect changes over time. The New York Timesused computer vision algorithms for the 2020 Summer Olympics to analyze and compare movements of athletes in events such as gymnastics. Reuters used image recognition to enhance in-house searches of the company’s vast video archive (note, speech-to-text transcripts for video was also part of this project). More than one news organization is using computer vision to detect fake images.
Interestingly, automated stories were categorized as planning, scheduling, and optimization rather than as NLP. It’s true that the day-to-day automation of various reports on financial statements, sporting events, real estate sales, etc., across a range of news organizations is handled with story templates — but the language in each story is adjusted algorithmically, and those algorithms have come at least in part from NLP.
The authors noted that within their limited sample, few projects involved social bots. “Most of the bots that we researched were news bots that write stories,” they said. It is true that “social bots such as Twitter bots do not necessarily use AI” — but in that case, the bot is going to use a rule-based system or de facto expert system, a category of AI the authors said was missing from the dataset.
Most of the projects in the dataset relied on external funding, and mainly from one source: Google’s Digital News Innovation Fund grants.
One thing I like about this research is that it does not conflate artificial intelligence and data journalism — which in my view is a serious flaw in much of the literature about AI in journalism. You might notice that in the foregoing summary, the only instances of AI contributing information to stories involved use of satellite imagery.
The authors of the article discussed above are Mathias-Felipe de-Lima-Santos of the University of Navarra, Spain, and Wilson Ceron of the Federal University of São Paulo, Brazil.
Most journalism investigations are unique. That precludes the time, expense and expertise required to develop an AI solution or tool to aid in one investigation, because it likely would not be usable in any other investigation.
Journalists’ salaries are far lower than the salaries of AI developers and data scientists. A news organization won’t hire AI experts to develop systems to aid in journalism investigations.
Data journalists do use a number of digital tools for cleaning, analyzing, and visualizing data, but it must be said that almost all of these tools are not part of what is called artificial intelligence. Spreadsheets, for example, are essential in data journalism but a far cry from AI. Stray points to other tools — for extracting information from digitized documents, or finding and eliminating duplicate records in datasets (e.g. with Dedupe.io). The line gets fuzzy when the journalist needs to train the tool so that it learns the particulars of the given dataset — by definition, that is machine learning. This training of an already-built tool, however, is immensely simpler than the thousands or even millions of training epochs overseen by computer scientists who develop new AI systems.
Stray clarifies his focus as “the application of AI theory and methods to problems that are unique to investigative reporting, or at least unsolved elsewhere.” He identifies these categories for successful uses of AI in journalism so far:
Document classification
Language analysis
Breaking news detection
Lead generation
Data cleaning
Stray’s journalism examples are cases covered previously. He acknowledges that the “same small set of examples is repeatedly discussed at data journalism conferences” and this “suggests that there are a relatively small number of cases in total” (page 1080).
Supervised document classification is a method for sorting a large number of documents into groups. For investigative journalists, this separates documents likely to be useful from others that are far less likely to be useful; human examination of the “likely” group is still needed.
By language analysis, Stray means use of natural language processing (NLP) techniques. These include unsupervised methods of sorting documents (or forum comments, social media posts, emails) into groups based on similarity (topic modeling, clustering), or determining sentiment (positive/negative, for/against, toxic/nontoxic), or other criteria. Language models, for example, can identify “named entities” such as people or “nationalities or religious or political groups” (NORP) or companies.
Breaking news detection: The standard example is the Reuters Tracer system, which monitors Twitter and alerts journalists to news events. The advantage is getting a head start of as much as 18 minutes over other news organizations that will cover the same event. I am not sure whether any other organization has ever developed a comparable system.
Lead generation is not exactly story discovery but more like “Here’s something you might want to investigate further.” It might pan out; it might not. Stray’s examples here are a bit weak, in my opinion, but the one for using face recognition to detect members of the U.S. Congress in photos uploaded by the public does set the imagination running.
Data cleaning is always necessary, usually tedious, and often takes more time than any other part of the reporting process. It makes me laugh when I hear data-science educators talk about giving their students nice, clean datasets, because real data in the real world is always dirty, and you cannot analyze it properly until it has been cleaned. Data journalists talk about this incessantly, and about reliable techniques not only for cleaning data but also for documenting every step of the process. Stray does not provide examples of using AI for data cleaning, but he devotes a portion of his article to this and data “wrangling” as areas he deems most suitable for AI solutions in the future.
When documents are extremely diverse in format and/or structure (e.g. because they come from different entities and/or were created for different purposes), it can be very difficult to extract data from them in any useful way (for example: names of people, street addresses, criminal charges) unless humans do it by hand. Stray calls it “a challenging research problem” (page 1090). Another challenge is linking disparate documents to one another, for which the ultimate case to date is the Panama Papers. Network analysis can be used (after named entities are extracted), but linkages will still need to be checked by humans.
Stray also (quite interestingly) wrote about what would be needed if AI systems were to determine newsworthiness — the elusive quality that all journalists swear they can recognize (much like Supreme Court Justice Potter Stewart’s famous claim about obscenity).
Conclusions
From my reading so far, I think there are two major applications of AI in the journalism field actually operating at present: production of automated news stories (within limited frameworks), and purpose-built systems for manipulating the content choices offered to users (recommendations and personalization). Automated stories or “robot journalism” have been around for at least seven or eight years now and have been written about extensively.
I’ve read (elsewhere) about efforts to catalog and mine gigantic archives of both video and photographs, and even to produce fully automated videos with machine-generated voiceover narration, but I think those are corporate strategies to extract value from existing resources rather than something intended to produce new journalism in the public interest. I also think those efforts might be taking place mainly outside the journalism area by now.
One thing that’s clear: The typical needs of an investigative journalism project (the highest-cost and possibly most important kind of journalism) are not easily solved by AI, even today. In spite of great advances in NLP, giant collections of documents must still be acquired piecemeal by humans, and while NLP can help with some parts of extracting valuable information from documents, in the end these stories require a great deal of human labor and time.
Another area not addressed in either of the two articles discussed here is verification and fact-checking. The ClaimReview Project is one approach to this, but it is powered by human fact-checkers, not AI. See also the conference paper The Quest to Automate Fact-Checking, presented at the 2015 Computation + Journalism Symposium.
I’ve been reading a lot about artificial intelligence and journalism lately. Yesterday I read two studies that examine the scholarly literature in this area. Both were published in 2021.
From the 209 articles, they identified these additional themes: audience, authorship, big data, chatbots, credibility, data journalism, ethics, events detection, fact-checking, online comments, personalization, production, social media, technologies, and theory.
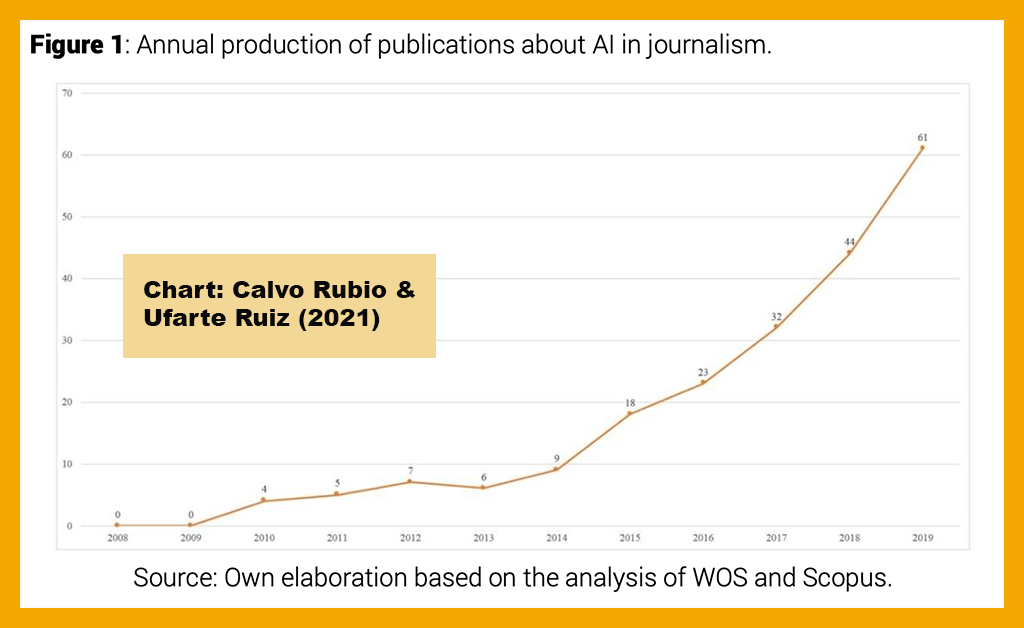
The number of articles published per year has increased sharply since 2015 (as you might expect). Sixty-one of the items were published in 2019, the final year in this study. The researchers also counted countries, institutions, citations, authors, and looked at collaborations, noting especially that collaboration among authors from different countries has been rare. One-third of the articles are from the U.S., while Germany, Ireland, Spain, and the U.K. combined account for more than one-third. The journal Digital Journalism had published the most articles (36).
Chart above by Calvo Rubio & Ufarte Ruiz (2021) shows number of publications per year, 2008–2019.
Keywords were supplied for 80 percent of the publications. Analysis identified more than 1,000 distinct keywords. These were the most common, in order starting with most-used:
Computational journalism
Automated journalism
Robot journalism
Journalism
Artificial intelligence
Data journalism
Algorithms
Automation
Algorithmic journalism
Social media
Big data
Other commonly seen concepts included: bots, fact checking, innovation, and natural language generation (NLG). Verification and personalized content also appeared in several articles.
The five most-cited articles (with more than 100 citations each) are from 2010 through 2015. The authors’ names will not surprise you if you have been following this field of study: C. W. Anderson, Mark Coddington, Nicholas Diakopoulos (three articles; two with co-authors).
The authors of the study described above are Luis Mauricio Calvo Rubio and María José Ufarte Ruiz, both of Universidad de Castilla-La Mancha.
"robot journalism" OR "computational journalism" OR "automated journalism" OR ("artificial intelligence" AND "journalism") OR ("artificial intelligence" AND "media")
After eliminating irrelevant articles, 358 were included for review, significantly more than the 209 items in the earlier study. In covering the entire year of 2020, which was not included in the earlier study, these researchers found there was a drop in the number of publications that year. This might be attributed to the global pandemic — although many articles for publication in 2020 would have been submitted in 2019, the processes of peer review and editorial oversight could well have been slowed by the burdens of that first pandemic year. For 2019, 74 articles were found. For 2020, the number was 43.
Like the other study, this one found a significant increase in relevant publications after 2015, but not the same consistently upward trajectory. Less than 13 percent of the items were published before 2015.
As in the other study, here too more than two-thirds of the articles came from Europe and North America. Only articles published in English were included, so this might not accurately represent all the research that exists in this topic area.
Multidisciplinary work “almost always comes from experts working in the same country. Eighty-six percent of the texts reviewed are written by authors whose universities are in the same country, and very often these authors belong to the same university” (page 5).
Six researchers accounted for 15 percent the articles in the sample (in order by number of publications): Nicholas Diakopoulos, Neil Thurman, Seth C. Lewis, Ester Appelgren, Eddy Borges-Rey, and Meredith Broussard. This was interesting to me, as I am not familiar with work by Appelgren or Thurman, while I have read all the others. (Both Appelgren and Thurman have published a lot about data journalism.)
Note, only those six authors have published four or more articles on this topic (within the 358 texts reviewed).
The researchers noted their surprise that so many of the items were “works of an essayistic nature, without either a well-defined methodology or precise research techniques.” Many articles “reflect generalist, introductory, or exploratory approaches.” In more recent publications, they noted “more specific research, with more consistent objectives, methodologies, or developments — and therefore closer to the orthodox research articles usually published in academic journals” (page 6). Qualitative methods predominate.
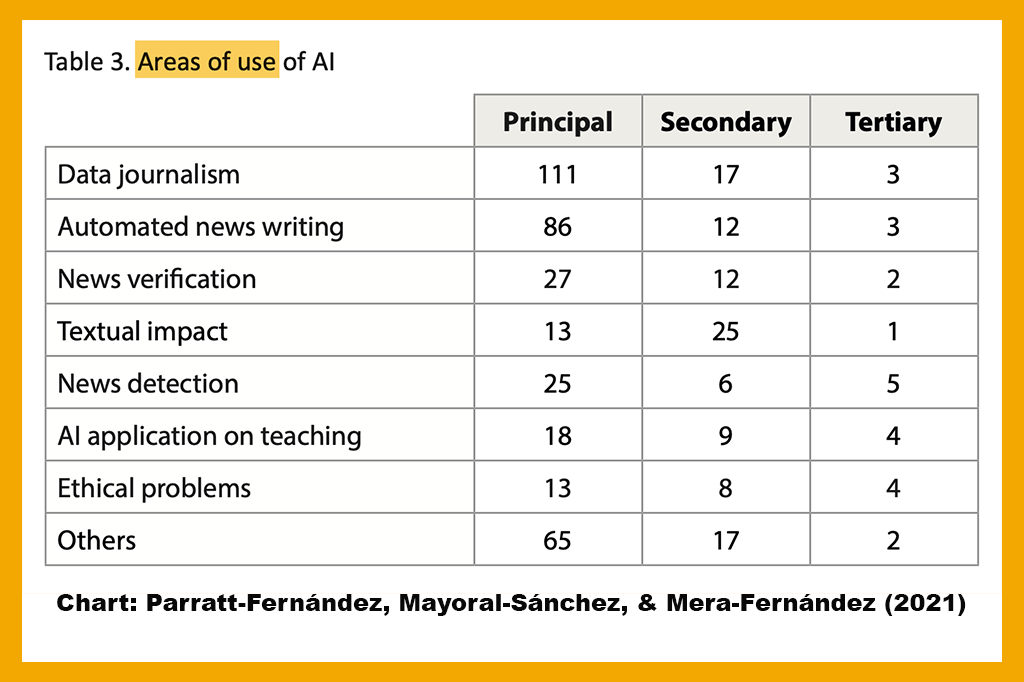
Based on their analysis of the 358 items, the researchers identified three principal areas for “application of artificial intelligence in journalism”: data journalism, robotic (or automated) news writing, and news verification (including “fake news”). It’s important to note, I think, that applied AIin journalism is not going to include uses of AI by the social media platforms (or search engines), which affect how news is distributed and shared.
Chart above by Parratt-Fernández, Mayoral-Sánchez, & Mera-Fernández (2021) shows areas of use of AI and number of articles that included each area as a primary, secondary or tertiary focus or topic.
Those three principal areas also exclude what is often called personalization, or news recommendation engines, which are applications of AI currently used by many news organizations. Distinct from the ordering and selection of news content by platforms (e.g. Facebook), this technology determines what individual users see in the apps or websites of the news organizations themselves, e.g. Recommended for You: How Newspapers Normalise Algorithmic News Recommendation to Fit Their Gatekeeping Role (2021).
Other prominent topic areas included “the impact of new AI technologies on the writing of journalistic texts” (I’m not sure how that differs from robotic news writing; maybe chatbots? SEO and clickbait?), and “the use of tools that allow information to be extracted and processed — e.g. from social networks — enabling journalists to discover a news event as quickly as possible” (page 7). The latter topic is also called “social media listening” (but not in this research paper). For example, when numerous mentions of an event such as an explosion, or a protest, or police action, start popping up in relation to one geographic location, an AI-trained model can recognize that it’s an unusual occurrence and send an alert to the newsroom.
The amount of academic research on data journalism was high from 2015 to 2017, but it has decreased since then and “experienced a considerable decline in 2020,” the authors noted. It’s kind of funny how data journalism often gets lumped in with artificial intelligence; much of data journalism has absolutely nothing to do with AI.
Ethical issues related to artificial intelligence and journalism have been neglected, according to this study’s findings. “The potential for development in this area is still enormous,” the authors said (page 8).
These researchers anticipate a need for new research on the professional routines and roles of journalists, assuming these will be affected by an increasing integration of AI systems into newswork. These changes will have an impact on journalist training requirements and university curricula as well.
Without falling into hyperbole, the authors speculated that AI represents “the next phase of technological revolution” in an industry that has been successively transformed by computerized page design and printing, internet news distribution, the rise of social media platforms, and viral disinformation campaigns and fake news (page 9).
The authors of the study described above are Sonia Parratt-Fernández, Javier Mayoral-Sánchez, and Montse Mera-Fernández, all of Universidad Complutense de Madrid.
Back in 2016, a professor teaching an online course about artificial intelligence developed a program that he called an AI teaching assistant. The program was given a name (“Jill Watson”) and referred to as “she.” A TEDx Talk video was published that same year.
A 2016 video features Professor Ashok Goel, who developed the “Jill Watson” teaching assistant.
In my recent reading about AI, I’ve found this case mentioned quite often. Sometimes it is generalized to imply that AI teaching assistants are in common use. Another implication is that AI teaching assistants (or even full-fledged AI teachers) are the solution to many challenges in K–12 education.
I wanted to get a better idea of what’s really going on, so I did a search at Google Scholar for “AI teaching assistant” (on March 16, 2022). I got “about 194 results,” which was more than I wanted to look at as search-result pages, so I downloaded 200 results using SerpApi and organized them in a spreadsheet. After eliminating duplicates, I read the titles and the snippets (brief text provided in the search results). I marked all items that appeared relevant — including many that are broadly about AI in education, but eliminating all those focused on how to teach about AI. I ended with 84 articles to examine more closely.
Quite a lot of these refer to the “Jill Watson” program. Many of the articles are speculative, describing potential uses of AI in education (including but not limited to virtual TAs), and contain no empirical research. Few of them could be considered useful for learning about AI teaching assistants — most of the authors have indicated no experience with using any AI teaching assistant themselves, let alone training one or programming one. Thus in most of the articles, the performance of an actual AI teaching assistant was not evaluated and was not even observed.
Kabudi, Pappas and Olsen (2021) conducted a much more rigorous search than mine. They analyzed 147 journal articles and conference presentations (from a total of 1,864 retrieved) about AI-enabled adaptive learning systems, including but not limited to intelligent tutoring systems. The papers were published from 2014 through 2020.
“There are few studies of AI-enabled learning systems implemented in educational settings,” they wrote (p. 2). The authors saw “a discrepancy between what an AI-enabled learning intervention can do and how it is actually utilised in practice. Arguably, users do not understand how to extensively use such systems, or such systems do not actually overcome complex challenges in practice, as the literature claims” (p. 7).
My interest in AI teaching assistants centers on whether I should devote attention to them in a survey course about artificial intelligence as it is used today. My conclusion is that much has been written about the possibilities of using “robot teachers,” intelligent tutoring systems, “teacherbots,” or virtual learning companions — but in fact the appearances of such systems in real classrooms (physical or online) with real students have been very few.
If classrooms are using commercial versions of AI teaching assistants, there is a lack of published research that evaluates the results or the students’ attitudes toward the experience.
A Page One story in Sunday’s New York Times detailed the assassination of a nuclear scientist in Iran in November: The Scientist and the A.I.-Assisted, Remote-Control Killing Machine (published online Sept. 18, 2021). I was taken aback by the phrase “AI-assisted remote-control killing machine” — going for the shock value!
Here’s a sample of the writing about the technology:
“The straight-out-of-science-fiction story of what really happened that afternoon and the events leading up to it, published here for the first time, is based on interviews with American, Israeli and Iranian officials …”
The assassination was “the debut test of a high-tech, computerized sharpshooter kitted out with artificial intelligence and multiple-camera eyes, operated via satellite and capable of firing 600 rounds a minute.”
“Unlike a drone, the robotic machine gun draws no attention in the sky, where a drone could be shot down, and can be situated anywhere, qualities likely to reshape the worlds of security and espionage” (boldface mine).
Most of the (lengthy) article is about Iran’s nuclear program and the role of the scientist who was assassinated.
The remote assassination system was built into the bed of a pickup truck, studded with “cameras pointing in multiple directions.” The whole rig was blown up after achieving its objective (although the gun robot was not destroyed as intended).
A crucial point about this setup is to understand the role of humans in the loop. People had to assemble the rig in Iran and drive the truck to its waiting place. A human operator “more than 1,000 miles away” was the actual sniper. The operation depended on satellites transmitting data “at the speed of light” between the truck and the distant humans.
So where does the AI enter into it?
There was an estimated 1.6-second lag between what the cameras saw and what the sniper saw, and a similar lag between the sniper’s actions and the firing of the gun positioned on the rig. There was the physical effect of the recoil of the gun (which affects the bullets’ trajectory). There was the speed of the car in which the nuclear scientist was traveling past the parked rig. “The A.I. was programmed to compensate for the delay, the shake and the car’s speed,” according to the article.
A chilling coda to this story: “Iranian investigators noted that not one of [the bullets] hit [the scientist’s wife], seated inches away, accuracy that they attributed to the use of facial recognition software.”
If you’re familiar with the work of Norbert Wiener (1894–1964), particularly on automated anti-aircraft artillery in World War II, you might be experiencing déjà vu. The very idea of a feedback loop came originally from Wiener’s observations of adjustments that are made as the gun moves in response to the target’s movements. To track and target an aircraft, the aim of the targeting weapon is constantly changing. Its new position continually feeds back into the calculations for when to fire.
The November assassination in Iran is not so much a “straight-out-of-science-fiction story” as it is one more incremental step in computer-assisted surveillance and warfare. An AI system using multiple cameras and calculating satellite lag times, the shaking of the truck and the weapon, and the movement of the target will be using faster computer hardware and more sophisticated algorithms than anything buildable in the 1940s — but its ancestors are real and solid, not imaginary.
Discussions and claims about artificial intelligence often conflate quite different types of AI systems. People need both to understand and to shape the technology that’s part of their day-to-day lives, but understanding is a challenge when descriptions and terms are used inconsistently — or over-broadly. This idea is part of a 2019 essay titled Artificial Intelligence — The Revolution Hasn’t Happened Yet, published in the Harvard Data Science Review.
“Academia will also play an essential role … in bringing researchers from the computational and statistical disciplines together with researchers from other disciplines whose contributions and perspectives are sorely needed — notably the social sciences, the cognitive sciences, and the humanities,” wrote Michael I. Jordan, whose lengthy job title is Pehong Chen Distinguished Professor in the Department of Electrical Engineering and Computer Science and the Department of Statistics at the University of California, Berkeley.
Jordan’s thoughtful, very readable essay is accompanied by 11 essay-length commentaries by various distinguished people and a rejoinder from Jordan himself.
In one of those commentaries, Barbara J. Grosz emphasized that “Rights of both individuals and society are at stake” in the shaping of technologies and practices built on AI systems. She said researchers and scholars in social science, cognitive science, and the humanities are vital participants in “determining the values and principles that will form the foundation” of a new AI discipline. Grosz is Higgins Research Professor of Natural Sciences at Harvard and the recipient of a lifetime achievement award from the Association for Computational Linguistics.
“When matters of life and well-being are at stake, as they are in systems that affect health care, education, work and justice, AI/ML systems should be designed to complement people, not replace them. They [the AI/ML systems] will need to be smart and to be good teammates,” Grosz wrote.
Concerns about ethical practices in the development of AI systems, in the collection and use of data, and in the deployment and use of technology based on AI systems are not new now, nor were they new in 2019. The idea of having the right mix of people in the room, at the table, however, has recently focused on racial, ethnic, socio-cultural and economic diversity more, perhaps, than on diversity of academic disciplines. Bringing in researchers from outside engineering, statistics, computer science, etc., can surface questions that would never arise in a group consisting only of engineers, statisticians, and computer scientists.
For me, those ideas dovetailed with a book chapter I happened to read on the previous day: “Beyond extraordinary: Theorizing artificial intelligence and the self in daily life,” in A Networked Self and Human Augmentics, Artificial Intelligence, Sentience (2018). Author Andrea L. Guzman wrote that in many senses, AI has become “ordinary” for us — one example is the voice assistants used by so many people in a completely everyday way. Intelligent robots and androids like Star Trek’s Lieutenant Commander Data, or evil world-controlling computer systems like Skynet in the Terminator movies, are part of a view of AI as “extraordinary” — which was the AI imagined for the future, before we had voice assistants and self-driving cars in the real world.
To be clear, there still exists the idea of extraordinary AI, super-intelligence or artificial general intelligence (AGI) — the “strong” AI that does not yet exist (and maybe never will). What Guzman describes is the way people today regard the AI–based tools and systems with which they interact. The AI that is, rather than the AI that might be.
How that connects to what both Jordan and Grosz wrote about interdisciplinary collaboration in AI development is this: Guzman is a journalism professor at Northern Illinois University, and she’s writing about the ways people communicate with a built system. Not interact with it, but communicate with it. When she investigated people’s perceptions and attitudes toward voice assistants, she realized that we don’t think about Siri and Alexa as intelligent devices. I was struck by Guzman’s description of how she initially approached her study and how her own perceptions changed.
“Conceptualizations of who we are in relation to AI, then, have formed around the myth that is AI” (Guzman, 2018, p. 87). “… I was applying a theory of the self that was developed around AI as extraordinary to the study of AI that was situated within the ordinary. The theoretical lens was an inadequate match for my subject” (Guzman, 2018, p. 90).