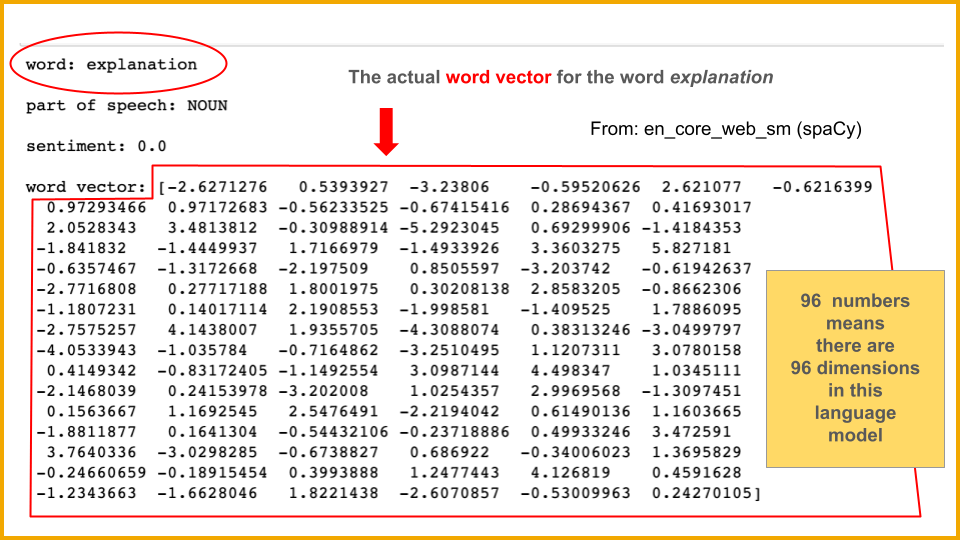
Let’s begin at the beginning, with Attention Is All You Need (Vaswani et al., 2017). This is a conference paper with eight authors, six of whom then worked at Google. They contended that neither recurrent neural networks nor convolutional neural networks are necessary for machine translation of languages, and hence the Transformer, “a new simple network architecture,” was born. (Note: It relies on feed-forward neural networks.)
Transformers are the basis for machine translation and other tasks relying on language models. GPT-3 has recently become infamous; others include BERT (from Google) and ELMo.
Before the work by Vaswani and his co-equal co-authors, progress in NLP was limited (although it had advanced a lot since 2012) because of the ways in which RNN models depend on the sequence and position of words in a text. Transformers eliminate those limitations. With recurrent neural networks, there are impediments to parallel processing. Other researchers had previously cracked that nut using ConvNets, but then other limitations were inherent (exponential increase in the number of computational operations). Transformers also eliminate those limitations.
So the Transformer was a first in NLP, a breakthrough. For machine translation, the paper claimed “a new state of the art” (p. 10).
I had learned that an encoder and a decoder connected by an attention module is a standard architecture for machine language translation, e.g. Google Translate. This was true before 2017, so what is the difference effected by the Transformer? It eliminates RNNs and ConvNets from the architecture, yes (“our model contains no recurrence and no convolution”) — but what else?
Attention used in a new way
“An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is computed as a weighted sum of the values, where the weight assigned to each value is computed by a compatibility function of the query with the corresponding key”(Vaswani et al., 2017, p. 3). I’m okay with that, although I doubt I would be able to explain it to my non–computer science students. (I do explain weights and features when I introduce neural nets to them, and I explain word vectors when we start NLP. The trouble is they don’t know how to write a program, and they certainly don’t understand what a function is.)
There are different attention functions that could be used. One is additive attention; another is dot-product attention, which is multiplicative rather than additive. Dot-product is “much faster and more space-efficient in practice.” Vaswani et al. used a scaled dot-product attention function (p. 4). They also used multi-head attention, meaning the model uses eight parallel attention layers, or heads. The explanation was a bit beyond me, but the gist is that the model can look at multiple things at the same time, like juggling more balls simultaneously.
Multi-head attention — plus the freedom of no-sequence, no-position — enables the Transformer to look at all the context for a word, and do it for multiple words at the same time.
With my rudimentary understanding of recurrent neural nets, I have a fuzzy idea of how this use of attention functions produces better results, mainly by being able to take in and compare more of the text, a little closer to the way human brains hold an entire conversation even though it’s not a literal “recording” of the exact conversation. The way we comprehend meaning when we read has to do with millions of associations built up over a lifetime, as well as many associations within that present text. We are not processing separate little slices of a sentence — our brains handle a text more holistically.
A Transformer does use word embeddings to convert the tokens (both inout and output) to vectors (Vaswani et al., 2017, p. 5). It uses softmax but no LSTMs (because, again, “no recurrence”).
Please help me, YouTube
I found a video (13:04) that helped me in my struggle to understand the Transformer architecture:
It was still a tough climb for me, but this video was particularly helpful with how multi-head attention improves the process. (Obviously the speed improvement is huge.)
Another helpful video (5:33) does a nice job summing up the sequence-based limitations of RNNs: “In general it’s easier for [RNNs] to capture relationships between points that are close to each other than it is to capture relationships between points that are very far from each other — say, several thousand points in the sequence.” In the paper, this is called “path length between long-range dependencies in the network” (Vaswani et al., 2017, p. 6) and identified as one of three motivations for developing the self-attention layers in Transformer.
In fact this second video is much better than the one above, but I liked that one when I watched it first, and maybe (haha!!) the order in which I watched them had an effect. The diagrams for self-attention in this shorter video are very good!
Back to Vaswani et al.
Speaking of self-attention — it was interesting that the authors thought it “could yield more interpretable models.” As in any hidden layer in any neural network, features are determined and weights set by the system itself, not by the human programmers. This is the “learning” in machine learning. The authors noted that the “individual attention heads clearly learn to perform different tasks,” and that many of them “appear to exhibit behavior related to the syntactic and semantic structure of the sentences” (p. 7; my italics).
Cool.
The results section of the paper describes performance using BLEU scores on two different NLP tasks (WMT 2014 English-to-German translation; WMT 2014 English-to-French translation) — reported as best-ever at that time — as well as record-breaking lower training costs, which means time to train the model factored by processor power used (number of GPUs, estimate of the number of floating-point operations).
The successor to the code on which this seminal paper was based is Trax, available on GitHub.
At the end of the paper (pages 13–15) there are math-free visualizations that illustrate what the attention mechanism does. These are well worth a look.
.

AI in Media and Society by Mindy McAdams is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
Include the author’s name (Mindy McAdams) and a link to the original post in any reuse of this content.
.