
I am fascinated by image recognition. I read about how ImageNet changed the whole universe of machine “vision” in 2009 in the excellent book Artificial Intelligence: A Guide for Thinking Humans, but I’m not going to discuss ImageNet in this post. (I will get to it eventually.)
To think about how a machine sees requires us first to think about human eyes vs. cameras. The machine doesn’t have a biological eyeball and an optic nerve and a brain. The machine might have one or more cameras to allow it to take in visual information.
Whether the machine has cameras or not, the images it receives are the same: digital images, made up entirely of pixels. This is true even if the visual inputs are video. The machine will need to sample that video, taking discrete frames from it to process and analyze.
So the first thing to absorb, as you begin to understand how a machine sees, is that it receives a grid of pixels. If it’s video, then there are a lot of separate grids. If it’s one still image, there is one grid. And how does the machine process that grid? It analyzes the differences between groups of pixels.
This 4-minute video, from an artist and programmer named Gene Kogan, helped me a lot.
Most people have an idea (possibly vague) of how the human brain works, with neurons kind of “wired together” in a network. When we imagine a computer neural network, most of us probably factor in that mental image of a brain full of neurons. This is both semi-accurate and wildly inaccurate.
In his video, Kogan points out that an image-recognition system uses a convolutional neural network, and this network has many, many layers.
When he’s clicking down the list in his video, Kogan is showing us what the different layers are “paying attention to” as the video is continuously chopped into one-frame segments. The mind-blowing thing (to me) is that the layers feed forward and backward to each other — ultimately producing the result he shows near the end, when he can hold a water bottle in front of his webcam, and the software says it sees a water bottle.
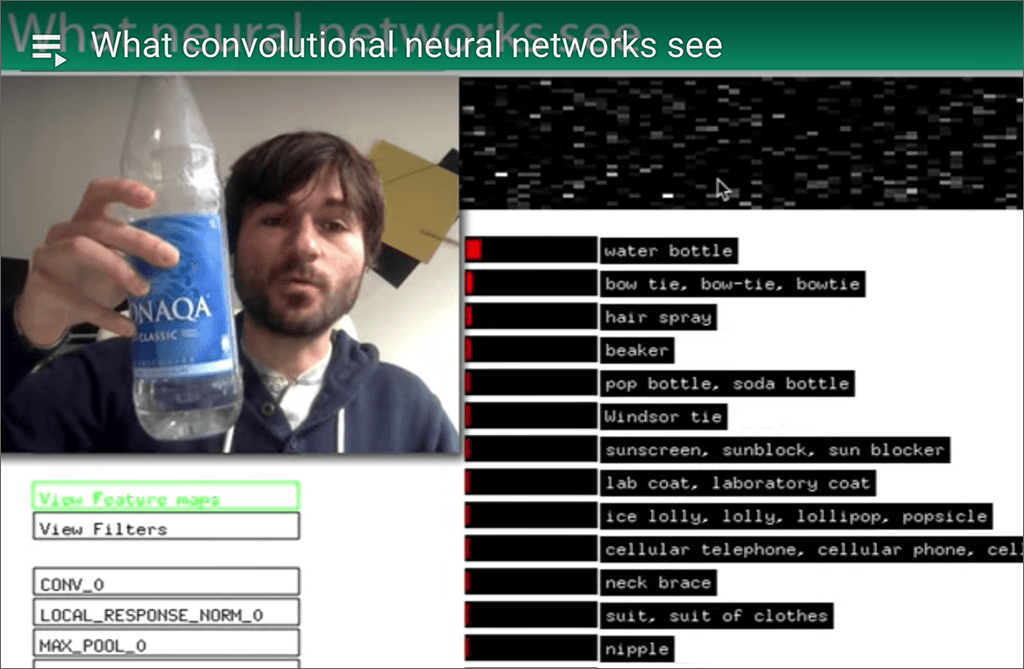
Notice too, that “water bottle” is the machine’s top guess at that moment. Its number 2 guess is “bow tie.” Its confidence in “water bottle” is not very high, as shown by the red bar to the left of the label. However, the machine’s confidence in “water bottle” is much higher than all the other things it determines it might be seeing in that frame.
After watching this video, I understood why super-fast graphics-processing hardware is so important to image recognition and machine vision.
In tomorrow’s post, I’m going to say a bit more about these ideas and share a completely different video that also helped me a lot in my attempt to understand how machines see.

AI in Media and Society by Mindy McAdams is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
Include the author’s name (Mindy McAdams) and a link to the original post in any reuse of this content.
.