
GPT-3 has to be the most-hyped AI technology of the past year. Headlines said its predecessor, GPT-2, was “too dangerous” to be released publicly. Then it was released. The world did not end.
Less than a year later, the more advanced (next generation) GPT-3 was released by OpenAI. Why are people so excited about GPT-3? See for yourself in the video below.
GPT-3 is a natural language generation (NLG) system. Given instructions about what you want, it writes original text that — in most (but not all) cases — sounds like a human wrote it. The technology could be used to rapidly write 10,000 fake user comments into a discussion forum, for example. Or 10,000 fake restaurant reviews.
Don’t worry about the first examples in the video showing GPT-3 writing computer code, if that’s not something you’re well acquainted with — it quickly moves on to show the system extracting text from long documents and writing summaries on the fly. The presenter does a good job of demonstrating the breadth and variety of tasks GPT-3 can be used for. You might be flat-out amazed.
Bear in mind that the examples shown in the video are different, separate applications of GPT-3. You don’t just install GPT-3 and it does all of those things.
Developers can apply to gain access to the GPT-3 API. This enables them to create applications that use GPT-3 but not to see or modify the actual code that makes GPT-3 work. You can view more examples of GPT-3 applications at that same link.
Another nice thing about the video above is the explanation of generative pre-training. Instead of training the GPT-3 model (or models) only with labeled data (supervised learning), the OpenAI researchers used “a semi-supervised approach for language understanding tasks using a combination of unsupervised pre-training and supervised fine-tuning.” The pre-training for GPT-2 included a dataset of more than 7,000 unpublished books “from a variety of genres including Adventure, Fantasy, and Romance.” Because entire books were used — instead of sentences separated from their context — the model was able to learn long-range structure.
GPT-3 used even more long-form texts for pre-training (described in a technical paper):
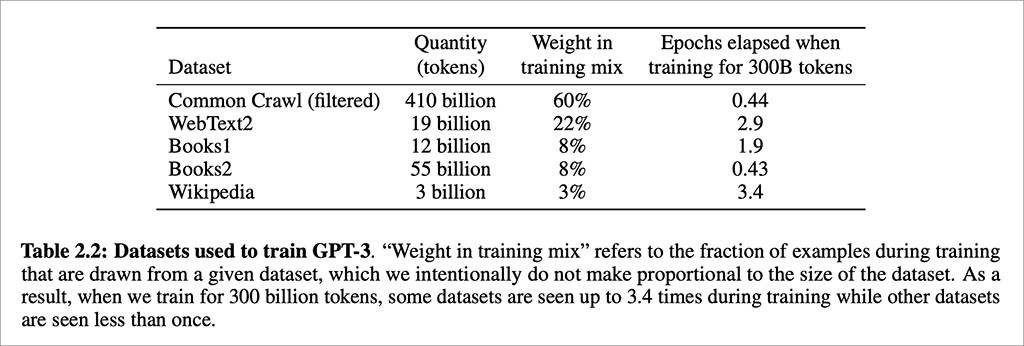
Once again we can see that tremendous advances in AI capability are made possible precisely because today’s computer hardware has the ability to run through enormous quantities of data very quickly. It’s not only that we now have billions of pages of text in digital form. It’s not just that we can store that Himalayan mountain range of data. It’s very much because processors are able to run multiple calculations simultaneously at lightning speed.
An important point about GPT-3 that’s not covered in the video: None of these applications, or GPT-3 itself, understands the meaning of the text that is being generated.
It’s going to be very easy for people to jump to conclusions about the “intelligence” of a computer system when it’s able to generate responses and explanations that are so human-like. There is no comprehension here. There is no knowledge of the world — there is only knowledge about language itself.
To learn more about how GPT-3 does what it does: GPT-3 Explained in Under 3 Minutes.

AI in Media and Society by Mindy McAdams is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
Include the author’s name (Mindy McAdams) and a link to the original post in any reuse of this content.
.