
I got my first look at spaCy, a Python library for natural language processing, near the end of 2019. I wanted to learn it but had too many other things to do. Fast-forward to now, almost 14 months into the pandemic, and I recently stumbled across spaCy’s own tutorial for learning to use the library.
The interactive tutorial includes videos, slides, and code exercises, and there is a GitHub repo. It is available in English, Deutsch, Español, Français, Português, 日本語, and 中文. Today I completed chapter 2. If you already know Python at, say, an intermediate level, check it out!

In chapter 1 (there are four chapters), I got a handle on part-of-speech tags, syntactic dependencies, and named entities. I learned that we can search on these, and also on words (tokens) related to combinations that we define. I’ve known about large-scale document searches (where a huge collection of documents is searched programmatically, usually to extract the most meaningful docs for some purpose — like a journalism investigation), and now I was getting a much better idea of how such searches can be designed.
SpaCy provides “pre-trained model packages,” meaning someone else has already done the hard work of machine learning/training to generate word vectors. There are packages of various sizes and in various languages. Loading a model provides various features (the bigger the model, the more features).
I think I was hooked as soon as I saw this and realized you could ask for all the MONEY entities, or all the ORG entities, in a document and evaluate them:

Then (still in chapter 1) I learned that I can easily define my own entities if the model doesn’t recognize the ones I need to find. I learned that if I don’t know what GPE is, I can enter spacy.explain("GPE") and spaCy will return 'Countries, cities, states' — sweet!
Then I learned about rule-based matching, and I thought: “Regular expressions, buh-bye!”
Chapter 1 didn’t really get deeply into lemmatization, but it offered this:

That was just chapter 1! Chapter 2 went further into creating your own named entities and using parts of speech as part of your search criteria. For example, if you want to find all instances where a particular entity (say, a city) is followed by a verb — any verb — you can do that. Or any part of speech. You can construct a complex pattern, mixing specific words, parts of speech, and selected types of entities. The pattern can include as many tokens as you want. (If you’re familiar with regex — all the regex things are available.)
You can determine whether phrases or sentences are similar to each other (although imperfectly).
I’m not entirely sure how I would use these, but I’m sure they’re good for something:
.root— the token that decides the category of the phrase.head— the syntactic “parent” that governs the phrase
There is an exercise in which I matched country names and their root head token (span.root.head), which gave me a bit of a clue as to how useful that might be in some circumstances.
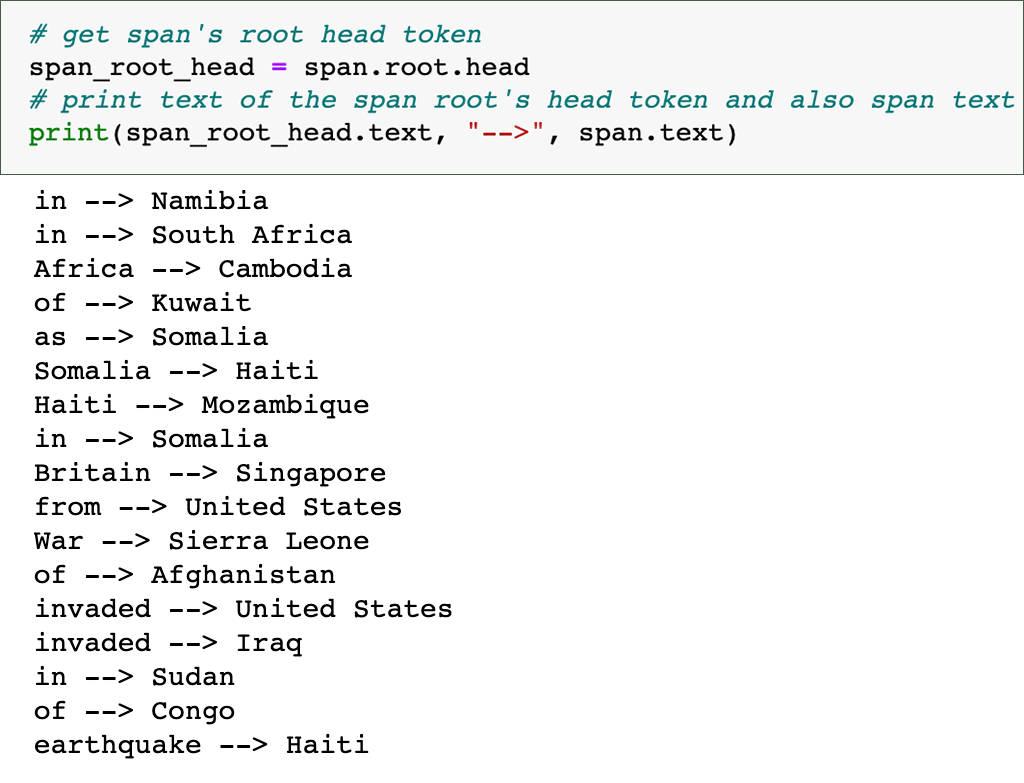
Also in chapter 2, I learned how to use an imported JSON file to add 240 country names as GPE entities — obviously, the imported terms could be any kind of entity.
So, I’m feeling very excited about spaCy! Halfway through the tutorial!

AI in Media and Society by Mindy McAdams is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
Include the author’s name (Mindy McAdams) and a link to the original post in any reuse of this content.