
To see for yourself the product, or end results, of an AI system, check out the Visual Chatbot online. It’s free. It’s fun.
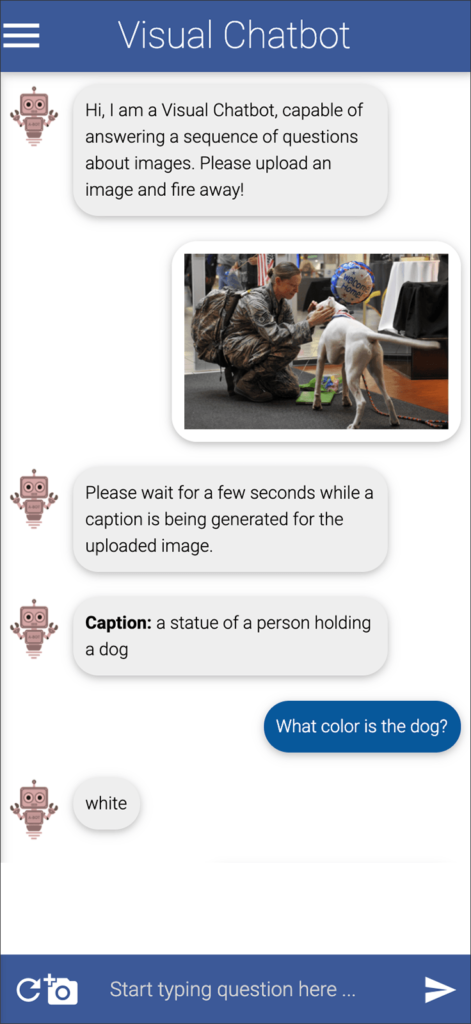
This app invites you to upload any image of your choice. It then generates a caption for that image. As you see above, the caption is not always 100 percent accurate. Yes, there is a dog in the photo, but there is no statue. There is a live person, who happens to be a soldier and a woman.
You can then have a conversation about the photo with the chatbot. The chatbot’s answer to my first question, “What color is the dog?”, was spot-on. Further questions, however, reveal limits that persist in most of today’s image-recognition systems.
The chat is still pretty awesome, though.

The image appears in chapter 4 of in Artificial Intelligence: A Guide for Thinking Humans, where author Melanie Mitchell uses it to discuss the complexity that we humans can perceive instantly in an image, but which machines are still incapable of “seeing.”
In spite of the mistakes the chatbot makes in its answers to questions about this image, it serves as a nice demonstration of how today’s chatbots do not need to follow a set script. Earlier chatbots were programmed with rules that stepped through a tree or flowchart of choices — if the human’s question contains x, then reply with y.
You can see more info about Visual Dialog if you’re curious about what the Visual Chatbot entails in terms of data, model, and/or code.
Below you can see some more questions I asked, with the answers from Visual Chatbot.

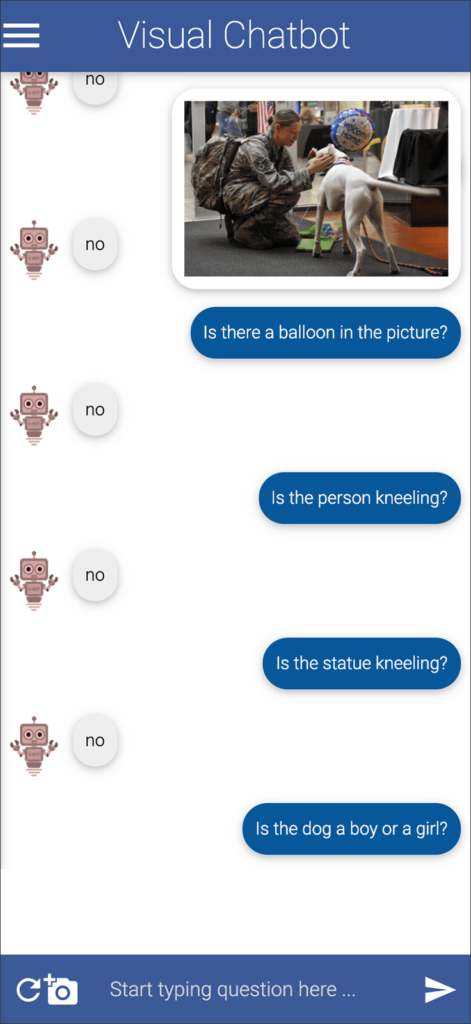
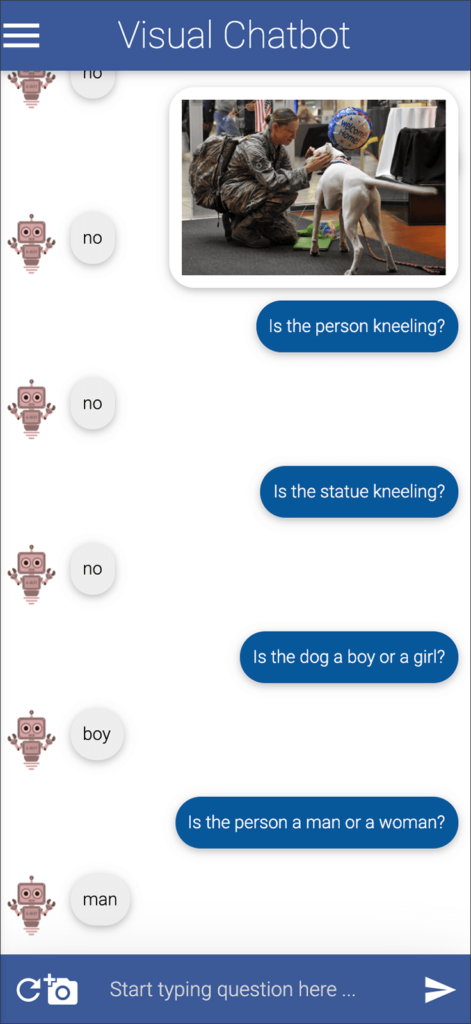
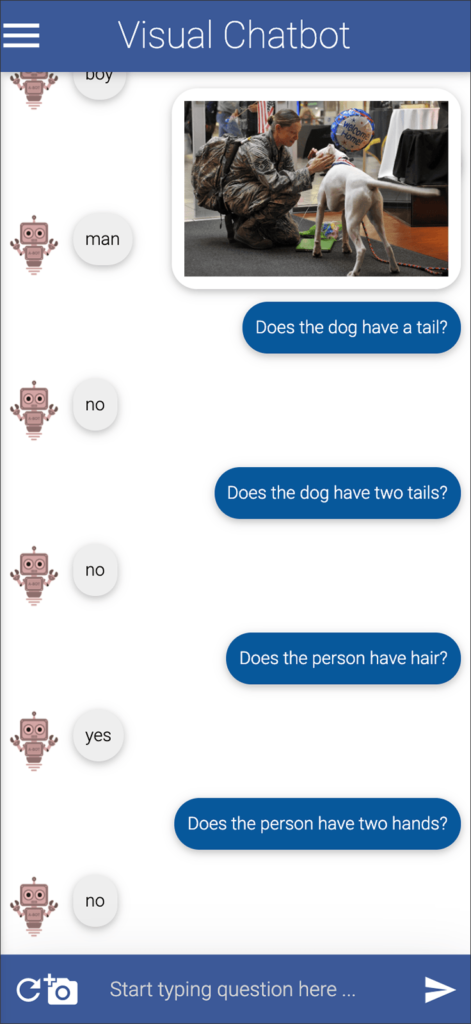
Some of my favorite wrong answers are on the last two screens. Note, you can ask questions that are not answered with only yes or no.

AI in Media and Society by Mindy McAdams is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
Include the author’s name (Mindy McAdams) and a link to the original post in any reuse of this content.
.