
MIT has a cool and easy-to-play game (okay, not really a game, but like a game) in which you get to choose what a self-driving car would do when facing an imminent crash situation.
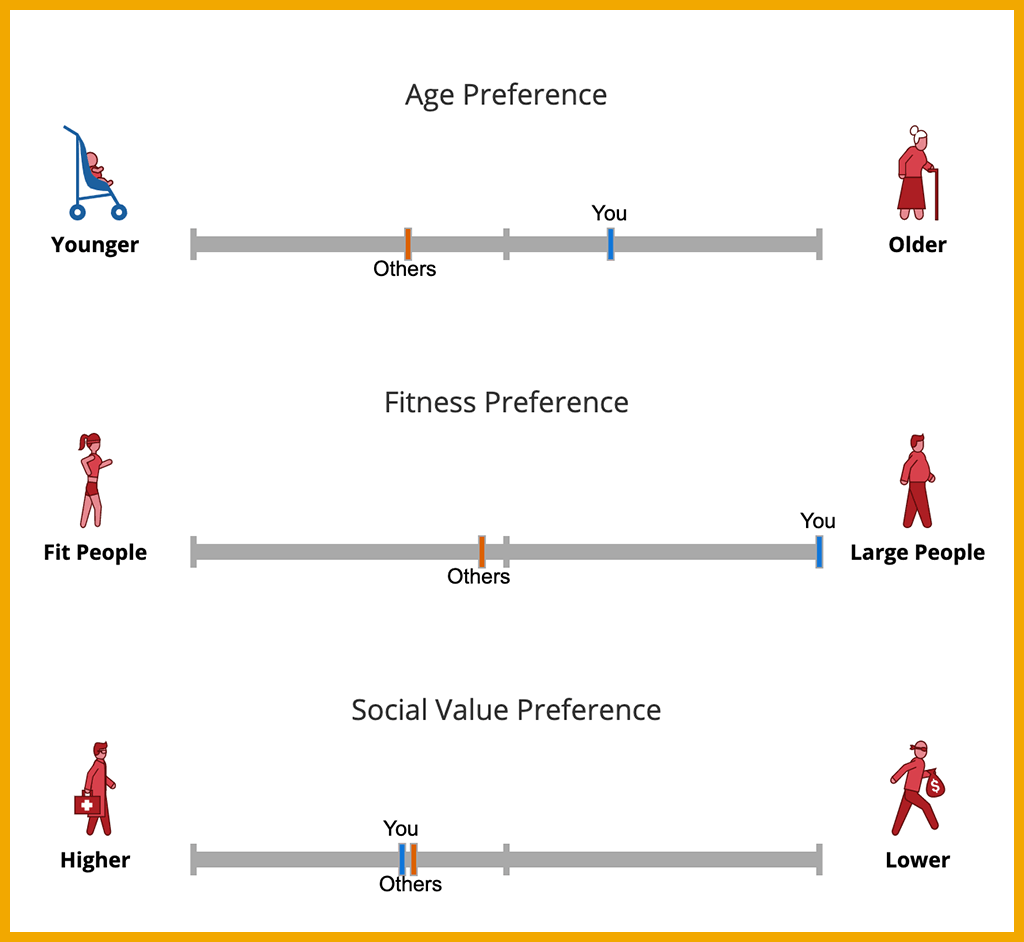
At the end of one round, you get to see how your moral choices measure up to those of other people who have played. Note that all the drawings of people in the game have distinct meanings. People inside the car are also represented. Try it yourself here.
It is often discussed how the split-second decision affecting who lives, who dies is one of the most difficult aspects of training an autonomous vehicle.
Imagine this scenario:
“The car is programmed to sacrifice the driver and the occupants to preserve the lives of bystanders. Would you get into that car with your child?”
—Meredith Broussard, The Atlantic, 2018
In a 2018 article, Self-Driving Cars Still Don’t Know How to See, data journalist and professor Meredith Broussard tackled this question head-on. We find that the way the question is asked elicits different answers. If you say the driver might die, or be injured, if a child in the street is saved, people tend to respond: Save the child! But if someone says, “You are the driver,” the response tends to be: Save me.
You can see the conundrum. When programming the responses into the self-driving car, there’s not a lot of room for fine-grained moral reasoning. The car is going to decide in terms of (a) Is a crash is imminent? (b) What options exist? (c) Does any option endanger the car’s occupants? (d) Does any option endanger other humans?
In previous posts, I’ve written a little about the weights and probability calculations used in AI algorithms. For the machine, this all comes down to math. If (a) is True, then what options are possible? Each option has a weight. The largest weight wins. The prediction of the “best outcome” is based on probabilities.

AI in Media and Society by Mindy McAdams is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
Include the author’s name (Mindy McAdams) and a link to the original post in any reuse of this content.
.
