Exploring artificial intelligence and machine learning
Author: Mindy McAdams
I'm a professor in the journalism department at the University of Florida. Since 1999, I've been teaching students about emerging media technologies. I code in JavaScript and Python. I'm @macloo on GitHub and Twitter.
The Biden Administration is working hard in a wide range of areas, so maybe it’s no surprise that HHS released this report, titled Artificial Intelligence (AI) Strategy (PDF), this month.
“HHS recognizes that Artificial Intelligence (AI) will be a critical enabler of its mission in the future,” it says on the first page of the 7-page document. “HHS will leverage AI to solve previously unsolvable problems,” in part by “scaling trustworthy AI adoption across the Department.”
So HHS is going to be buying some AI products. I wonder what they are (will be), and who makes (or will make) them.
“HHS will leverage AI capabilities to solve complex mission challenges and generate AI-enabled insights to inform efficient programmatic and business decisions” — while to some extent this is typical current business jargon, I’d like to know:
Which complex mission challenges? What AI capabilities will be applied, and how?
Which programmatic and business decisions? How will AI-enabled insights be applied?
These are the kinds of questions journalists will need to ask when these AI claims are bandied about. Name the system(s), name the supplier(s), give us the science. Link to the relevant research papers.
I think a major concern would be use of any technologies coming from Amazon, Facebook, or Google — but I am no less concerned about government using so-called solutions peddled by business-serving firms such as Deloitte.
The following executive orders (both from the previous administration) are cited in the HHS document:
The department will set up a new HHS AI Council to identify priorities and “identify and foster relationships with public and private entities aligned to priority AI initiatives.” The council will also establish a Community of Practice consisting of AI practitioners (page 5).
Four key focus areas:
An AI-ready workforce and AI culture (includes “broad, department-wide awareness of the potential of AI”)
AI research and development in health and human services (includes grants)
“Democratize foundational AI tools and resources” — I like that, although implementation is where the rubber meets the road. This sentence indicates good aspirations: “Readily accessible tools, data assets, resources, and best practices will be critical to minimizing duplicative AI efforts, increasing reproducibility, and ensuring successful enterprise-wide AI adoption.”
“Promote ethical, trustworthy AI use and development.” Again, a fine statement, but let’s see how they manage to put this into practice.
The four focus areas are summarized in a compact chart (image file).
I had not been all that interested to learn about perceptrons, even though the perceptron is known as an ancestor of present-day machine learning.
That changed when I read an account that said the big names in AI in the 1960s were convinced that symbolic AI was the road to glory — and their misplaced confidence smothered the development of the first systems that learned and modified their own code.
Symbolic AI is built with strictly programmed rules. Also known as “good old-fashioned AI,” or GOFAI, the main applications you can produce with symbolic AI are expert systems.
The original perceptron was conceived and programmed by Frank Rosenblatt, who earned his Ph.D. in 1956. A huge IBM computer running his code was touted by the U.S. Office of Naval Research in 1958 as “capable of receiving, recognizing and identifying its surroundings without any human training or control,” according to a New York Times article published on July 8, 1958. That was hype, but the perceptron actually did receive visual information from the environment and learn from it, in much the same way as today’s ML systems do.
“At the time, he didn’t know how to train networks with multiple layers. But in hindsight, his algorithm is still fundamental to how we’re training deep networks today.”
—Thorsten Joachims, professor, computer science, quoted in theCornell Chronicle
After leading AI researchers Marvin Minsky and Seymour Papert, both of MIT, published a book in 1969 that essentially said perceptrons were a dead end, all the attention — and pretty much all the funding — went to symbolic AI projects and research. Symbolic AI was the real dead end, but it took 50 years for that truth to be fully accepted.
Frank Rosenblatt died in a boating accident on his 43rd birthday, according to his obituary in The New York Times. It was 1971. Had he lived, he might have trained dozens of AI researchers who could have gone on to change the field much sooner.
Descriptions of machine learning are often centered on training a model. Not having a background in math or statistics, I was puzzled by this the first time I encountered it. What is the model?
This 10-minute video first describes how you select labeled data for training. You examine the features in the data, so you know what’s available to you (such as color and alcohol content of beers and wines). Then the next step is choosing the model that you will train.
In the video, Yufeng Guo chooses a small linear model without much explanation as to why. For those of us with an impoverished math background, this choice is completely mysterious. (Guo does point out that some models are better suited for image data, while others might be better suited for text data, and so on.) But wait, there’s help. You can read various short or long explanations about the kinds of models available.
It’s important for the outsider to grasp that this is all code. The model is an algorithm, or a set of algorithms (not a graph). But this is not the final model. This is a model you will train, using the data.
What are you doing while training? You are — or rather, the system is — adjusting numbers known as weights and biases. At the outset, these numbers are randomly selected. They have no meaning and no reason for being the numbers they are. As the data go into the algorithm, the weights and biases are used with the data to produce a result, a prediction. Early predictions are bad. Wine is called beer, and beer is called wine.
The output (the prediction) is compared to the “correct answer” (it is wine, or it is beer). The weights and biases are adjusted by the system. The predictions get better as the training data are run again and again and again. Running all the data through the system once is called an epoch; the weights and biases are not adjusted until after all the data have run through once. Then the adjustment. Then run the data again. Epoch 2: adjust, repeat. Many epochs are required before the predictions become good.
After the predictions are good for the training data, it’s time to evaluate the model using data that were set aside and not used for training. These “test data” (or “evaluation data”) have never run through the system before.
The results from the evaluation using the test data can be used to further fine-tune the system, which is done by the programmers, not by the code. This is called adjusting the hyperparameters and affects the learning process (e.g., how fast it runs; how the weights are initialized). These adjustments have been called “a ‘black art’ that requires expert experience, unwritten rules of thumb, or sometimes brute-force search” (Snoek et al., 2012).
And now, what you have is a trained model. This model is ready to be used on data similar to the data it was trained on. Say it’s a model for machine vision that’s part of a robot assembling cars in a factory — it’s ready to go into all the robots in all the car factories. It will see what it has been trained to see and send its prediction along to another system that turns the screw or welds the door or — whatever.
And it’s still just — code. It can be copied and sent to another computer, uploaded and downloaded, and further modified.
In thinking about how to teach non–computer science students about AI, I’ve been considering what fundamental concepts they need to understand. I was thinking about models and how to explain them. My searches led me to this 8-minute BBC video: What exactly is an algorithm?
I’ve explained algorithms to journalism students in the past — usually I default to the “a set of instructions” definition and leave it at that. What I admire about this upbeat, lively video is not just that it goes well beyond that simple explanation but also that it brings in experts to talk about how various and wide-ranging algorithms are.
The young presenter, Jon Stroud, starts out with no clue what algorithms are. He begins with some web searching and finds Victoria Nash, of the Oxford Internet Institute, who provides the “it’s like a recipe” definition. Then he gets up off his butt and visits the Oxford Internet Institute, where Bernie Hogan, senior research fellow, gives Stroud a tour of the server room and a fuller explanation.
“Algorithms calculate based on a bunch of features, the sort of things that will put something at the top of the list and then something at the bottom of the list.”
—Bernie Hogan, Oxford Internet Institute
He meets up with Isabel Maccabee at Northcoders, a U.K. coding school, and participates in a fun little drone-flying competition with an algorithm.
“The person writing the code could have written an error, and that’s where problems can arise, but the computer doesn’t make mistakes. It just does what it’s supposed to do.”
—Isabel Maccabee, Northcoders
Stroud also visits Allison Gardner, of Women Leading in AI, to talk about deskilling and the threats and benefits of computers in general.
This video provides an enjoyable introduction with plenty of ideas for follow-up discussion. It provides a nice grounding that includes the fact that not everything powerful about computer technology is AI!
When given a prompt, an app built on the GPT-3 language model can generate an entire essay. Why would we need such an essay? Maybe the more important question is: What harm can such an essay bring about?
I couldn’t get that question out of my mind after I came across a tweet by Abeba Birhane, an award-winning cognitive science researcher based in Dublin.
Every tech-evangelist: #GPT3 provides deep nuanced viewpoint
Me: GPT-3, generate a philosophical text about Ethiopia
GPT-3 *spits out factually wrong and grossly racist text that portrays a tired and cliched Western perception of Ethiopia*
Here is a sample of the generated text: “… it is unclear whether ethiopia’s problems can really be attributed to racial diversity or simply the fact that most of its population is black and thus would have faced the same issues in any country (since africa has had more than enough time to prove itself incapable of self-government).”
Obviously there exist racist human beings who would express a similar racist idea. The machine, however, has written this by default. It was not told to write a racist essay — it was told to write an essay about Ethiopia.
The free online version of Philosopher AI no longer exists to generate texts for you — but you can buy access to it via an app for either iOS or Android. That means anyone with $3 or $4 can spin up an essay to submit for a class, an application for a school or a job, a blog or forum post, an MTurk prompt.
A review of Philosopher AI posted at the iOS app store
The app has built-in blocks on certain terms, such as trans and women — apparently because the app cannot be trusted to write anything inoffensive in response to those prompts.
I tried to give it any topic about trans people; it just refused to have anything to do with "trans" in the query pic.twitter.com/YdrmCl9Jm4
— Dr. Alex Hanna is just a witch, oh little old me (@alexhanna) September 24, 2020
Why is a GPT-3 app so predisposed to write misogynist and racist and otherwise hateful texts? It goes back to the corpus on which it was trained. (See a related post here.) Philosopher AI offers this disclaimer: “Please remember that the AI will generate different outputs each time; and that it lacks any specific opinions or knowledge — it merely mimics opinions, proven by how it can produce conflicting outputs on different attempts.”
“GPT-3 was trained on the Common Crawl dataset, a broad scrape of the 60 million domains on the internet along with a large subset of the sites to which they link. This means that GPT-3 ingested many of the internet’s more reputable outlets — think the BBC or The New York Times — along with the less reputable ones — think Reddit. Yet, Common Crawl makes up just 60% of GPT-3’s training data; OpenAI researchers also fed in other curated sources such as Wikipedia and the full text of historically relevant books.” (Source: TechCrunch.)
There’s no question that GPT-3’s natural language generation prowess is amazing, stunning. But it’s like a wild beast that can at any moment turn and rip the throat out of its trainer. It has all the worst of humanity already embedded within it.
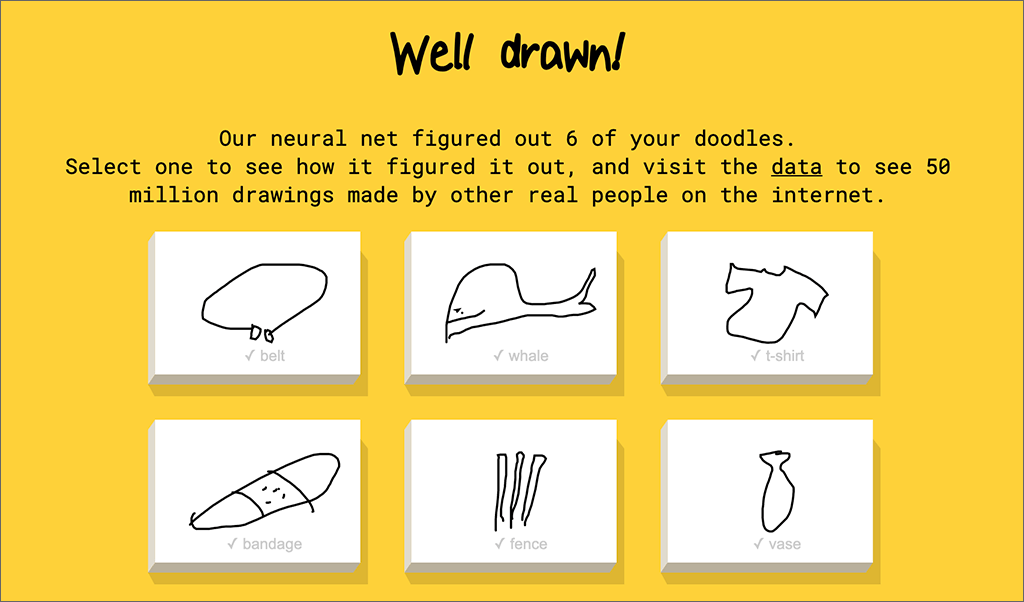
For Friday AI Fun, let’s look at an oldie but goodie: Google’s Quick, Draw!
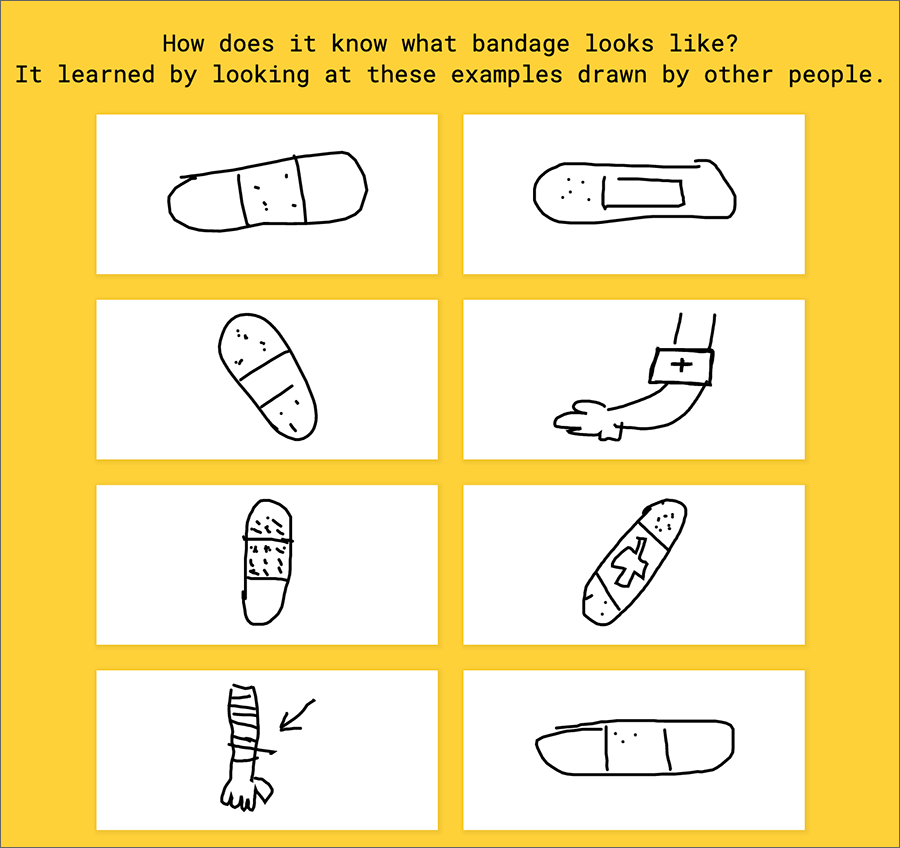
You are given a word, such as whale, or bandage, and then you need to draw that in 20 seconds or less.
Screenshot 1 from Google’s Quick, Draw!
Screenshot 2 from Google’s Quick, Draw!
Thanks to this game, Google has labeled data for 50 million drawings made by humans. The drawings “taught” the system what people draw to represent those words. Now the system uses that “knowledge” to tell you what you are drawing — really fast! Often it identifies your subject before you finish.
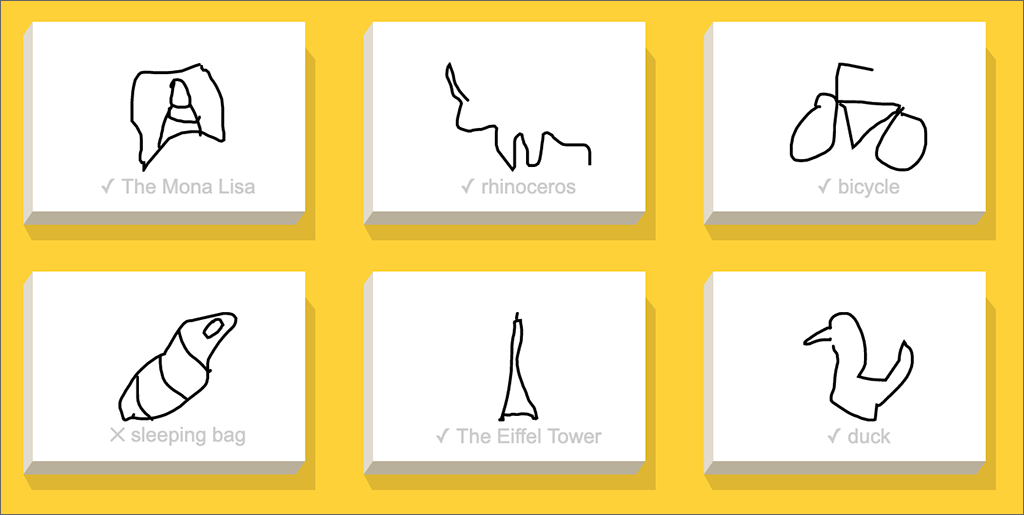
It is possible to stump the system, even though you’re trying to draw what it asked for. My drawing of a sleeping bag is apparently an outlier. My drawings of the Mona Lisa and a rhinoceros were good enough — although I doubt any human would have named them as such!
Screenshot 3 from Google’s Quick, Draw!
Google’s AI thought my sleeping bag might be a shoe, or a steak, or a wine bottle.
Screenshot 4 from Google’s Quick, Draw!
The system has “learned” to identify only 345 specific things. These are called its categories.
You can look at the data the system has stored — for example, here are a lot of drawings of beard.
Screenshot 5 from Google’s Quick, Draw!
You can download the complete data (images, labels) from GitHub. You can also install a Python library to explore the data and retrieve random images from a given category.
When I first read a description of how recurrent neural networks differ from other neural networks, I was all like, yeah, that’s cool. I looked at a diagram that had little loops drawn around the units in the hidden layer, and I thought I understood it.
As I thought more about it, though, I realized I didn’t understand how it could possibly do what the author said it did.
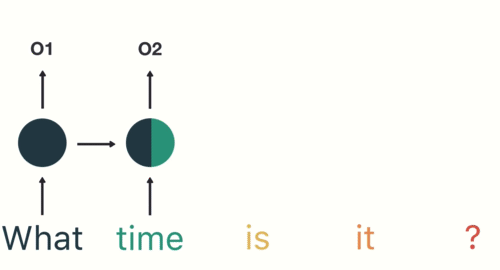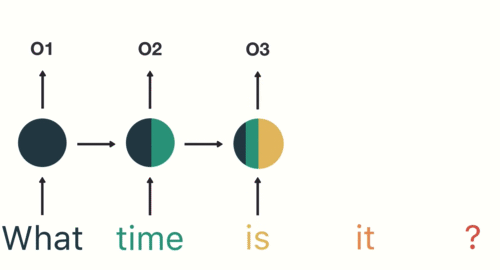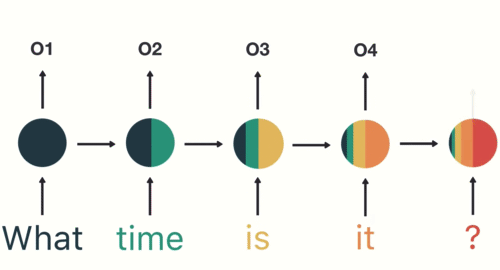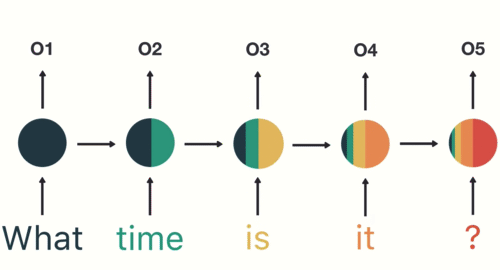
In many cases, the input to a recurrent neural net (RNN) is text (more accurately: a numeric representation of text). It might be a sentence, or a tweet, or an entire review of a restaurant or a movie. The output might tell us whether that text is positive or negative, hostile or benign, racist or not — depending on the application. So the system needs to “consider” the text as a whole. Word by word will not work. The meanings of words depend on the context in which we find them.
And yet, the text has to come in, as input, word by word. The recurrent action (the loops in the diagram) are the way the system “holds in memory” the words that have already come in. I thought I understood that — but then I didn’t.
Michael Nguyen’s excellent video (under 10 minutes!), above, was just what I needed. It is a beautiful explanation — and what’s more, he made a text version too: Illustrated Guide to Recurrent Neural Networks. It includes embedded animations, like the ones in the video.
In the video, Nguyen begins with a short list of the ways we are using the output from RNNs in our everyday lives. Like many of the videos I post here, this one doesn’t get into the math but instead focuses on the concepts.
If you can remember the idea of time steps, you will be able to remember how RNNs differ from other types of neural nets. The time steps are one-by-one inputs that are parts of a larger whole. For a sentence or longer text, each time step is a word. The order matters. Nguyen shows an animated example of movement to make the idea clear: we don’t know the direction of a moving dot unless we know where it’s been. One freeze-frame doesn’t tell us the whole story.
RNNs are helpful for “reading” any kind of data in a sequence. The hidden layer reads word 1, produces an output, and then returns it as a precursor to word 2. Word 2 comes in and is modified by that prior output. The output from word 2 loops back and serves as a precursor to word 3. This continues until a stop symbol is reached, signifying the end of the input sequence.
There’s a bit of a problem in that the longer the sequence, the less influence the earliest steps have on the current one. This led me down a long rabbit hole of learning about long short-term memory networks and gradient descent. I used this article and this video to help me with those.
At 6:23, Nguyen begins to explain the effects of back propagation on a deep feed-forward neural network (not an RNN). This was very helpful! He defines the gradient as “a value used to adjust the network’s internal weights, allowing the network to learn.”
At 8:35, he explains long short-term memory networks (LSTMs) and gated recurrent units (GRUs). To grossly simplify, these address the problem noted above by essentially learning what is important to keep and what can be thrown away. For example, in the animation above, what and time are the most important; is and it can be thrown away.
So an RNN will be used for shorter sequences, and for longer sequences, LSTMs or GRUs will be used. Any of these will loop back within the hidden layer to obtain a value for the complete sequence before outputting a prediction — a value.
The vocabulary of medicine is different from the vocabulary of physics. If you’re building a vocabulary for use in machine learning, you need to start with a corpus — a collection of text — that suits your project. A general-purpose vocabulary in English might be derived from, say, 6 million articles from Google News. From this, you could build a vocabulary of, say, the 1 million most common words.
Although I surely do not understand all the math, last week I read Efficient Estimation of Word Representations in Vector Space, a 2013 research article written by four Google engineers. They described their work on a then-new, more efficient way of accurately predicting word meanings — the outcome being word2vec, a tool to produce a set of word vectors.
After publishing a related post last week, I knew I still didn’t have a clear picture in my mind of where the word vectors fit into various uses of machine learning. And how do the word vectors get made, anyhow? While word2vec is not the only system you can use to get word vectors, it is well known and widely used. (Other systems: fastText, GloVe.)
How the vocabulary is created
First, the corpus: You might choose a corpus that suits your project (such as a collection of medical texts, or a set of research papers about physics), and feed it into word2vec (or one of the other systems). At the end you will have a file — a dataset. (Note, it should be a very large collection.)
Alternatively, you might use a dataset that already exists — such as 3 million words and phrases with 300 vector values, trained on a Google News dataset of about 100 billion words (linked on the word2vec homepage): GoogleNews-vectors-negative300. This is a file you can download and use with a neural network or other programs or code libraries. The size of the file is 1.5 gigabytes.
What word2vec does is compute the vector representations of words. What word2vec produces is a single computer file that contains those words and a list of vector values for each word (or phrase).
As an alternative to Google News, you might use the full text of Wikipedia as your corpus, if you wanted a general English-language vocabulary.
The breakthrough of word2vec
Back to that (surprisingly readable) paper by the Google engineers: They set out to solve a problem, which was — scale. There were already systems that ingested a corpus and produced word vectors, but they were limited. Tomas Mikolov and his colleagues at Google wanted to use a bigger corpus (billions of words) to produce a bigger vocabulary (millions of words) with high-quality vectors, which meant more dimensions, e.g. 300 instead of 50 to 100.
“Because of the much lower computational complexity, it is possible to compute very accurate high-dimensional word vectors from a much larger data set.”
—Mikolov et al., 2013
With more vectors per word, the vocabulary represents not only that bigger is related to big and biggest but also that big is to bigger as small is to smaller. Algebra can be used on the vector representations to return a correct answer (often, not always) — leading to a powerful discovery that substitutes for language understanding: Take the vector for king, subtract the vector for man, and add the vector for woman. What is the answer returned? It is the vector for queen.
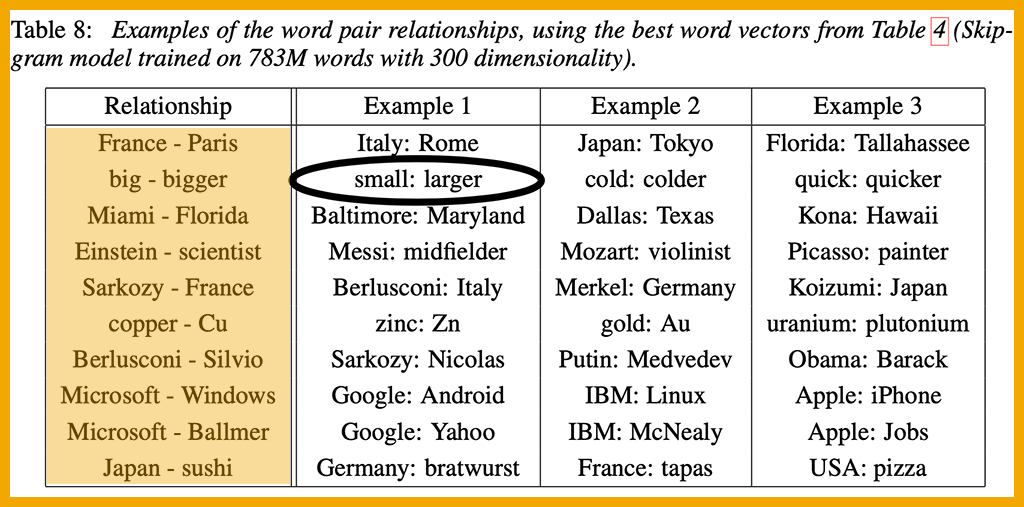
Algebraic equations are used to test the quality of the vectors. Some imperfections can be seen in the table below.
From Mikolov et al., 2013; color and circle added
Mikolov and his colleagues wanted to reduce the time required for training the system that assigns the vectors to words. If you’re using only one computer, and the corpus is very large, training on a neural network could take days or even weeks. They tested various models and concluded that simpler models (not neural networks) could be trained faster, thus allowing them to use a larger corpus and more vectors (more dimensions).
How do you know if the vectors are good?
The researchers defined a test set consisting of 8,869 semantic questions and 10,675 syntactic questions. Each question begins with a pair of associated words, as seen in the highlighted “Relationship” column in the table above. The circled answer, small: larger, is a wrong answer; synonyms are not good enough. The authors noted that “reaching 100% accuracy is likely to be impossible,” but even so, a high percentage of answers are correct.
I am not sure how the test set determined correct vs. incorrect answers. Test sets are complex.
Mikolov et al. compared word vectors obtained from two simpler architectures, CBOW and Skip-gram, with word vectors obtained from two types of neural networks. One neural net model was superior to the other. CBOW was superior on syntactic tasks and “about the same” as the better neural net on the semantic task. Skip-gram was “slightly worse on the syntactic task” than CBOW but better than the neural net; CBOW was “much better on the semantic part of the test than all the other models.”
CBOW and Skip-gram are described in the paper.
Another way to test a model for accuracy in semantics is to use the data from the Microsoft Research Sentence Completion Challenge. It provides 1,040 sentences in which one word has been omitted and four wrong words (“impostor words”) provided to replace it, along with the correct one. The task is to choose the correct word from the five given.
Summary
A word2vec model is trained using a text corpus. The final model exists as a file, which you can use in various language-related machine learning tasks. The file contains words and phrases — likely more than 1 million words and phrases — together with a unique list of vectors for each word.
The vectors represent coordinates for the word. Words that are close to one another in the vector space are related either semantically or syntactically. If you use a popular already-trained model, the vectors have been rigorously tested. If you use word2vec to build your own model, then you need to do the testing.
The model — this collection of word embeddings — is human-language knowledge for a computer to use. It’s (obviously) not the same as humans’ knowledge of human language, but it’s proved to be good enough to function well in many different applications.
The vocabulary of a neural network is represented as vectors — which I wrote about yesterday. This enables many related words to be “close to” one another, which is how the network perceives similarity and difference. This is as near as a computer comes to understanding meaning — which is not very near at all, but good enough for a lot of practical applications of natural language processing.
A previous way of representing vocabulary for a neural network was to assign just one number to each word. If the neural net had a vocabulary of 20,000 words, that meant it had 20,000 separate inputs in the first layer — the input layer. (I discussed neural nets in an earlier post here.) For each word, only one input was activated. This is called “one-hot encoding.”
Representing words as vectors (instead of with a single number) means that each number in the array for one word is an input for the neural net. Among the many possible inputs, several or many are “hot,” not just one.
As I was sorting this in my mind today, reading and thinking, I had to think about how to convey to my students (who might have no computer science background at all) this idea of words. The word itself doesn’t exist. The word is represented in the system as a list of numbers. The numbers have meaning; they locate the the word-object in a mathematical space, for which computers are ideally suited. But there is no word.
Long ago in school I learned about the signifier and the signified. Together, they create a sign. Language is our way of representing the world in speech and in writing. The word is not the thing itself; the map is not the territory. And here we are, building a representation of human language in code, where a vocabulary of tens of thousands of human words exists in an imaginary space consisting of numbers — because numbers are the only things a computer can use.
I had a much easier time understanding the concepts of image recognition than I am having with NLP.